
引言
本文采用 EclipseLink 的 JPA 实现,相关 FleaJPAQuery 的接入使用请移步我的 另外几篇博文。

首先讨论一下,为了实现 JPA 分表查询,我们需要做哪些事情:
- 分表规则定义(即从主表到分表的转换实现)
- 分表查询实现(即JPA标准化查询组件根据分表规则查询具体分表)
1. JPA标准化查询
在JPA中,实体对应的表由如下注解定义:
1
2
| @Entity
@Table(name = "flea_login_log")
|
如上可见,实体类实际上只会对应一个表名,单纯从这里是无法实现分表查询。
那么既然这样无法分表,我们选择退而求其次,看看表名是什么时候,被那个对象使用,因为我们可以确认查询最后的表名,一定是使用的注解定义的表名。
下面是调试过程的发现:
com.huazie.frame.db.jpa.common.FleaJPAQuery
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public void init(EntityManager entityManager, Class sourceClazz, Class resultClazz) {
this.entityManager = entityManager;
this.sourceClazz = sourceClazz;
this.resultClazz = resultClazz;
criteriaBuilder = entityManager.getCriteriaBuilder();
if (ObjectUtils.isEmpty(resultClazz)) {
criteriaQuery = criteriaBuilder.createQuery(sourceClazz);
} else {
criteriaQuery = criteriaBuilder.createQuery(resultClazz);
}
root = criteriaQuery.from(sourceClazz);
}
|
如下两张图是根SQL表达式对象 Root 的Debug视图,发现存储实际表名的是 DatabaseTable 对象。
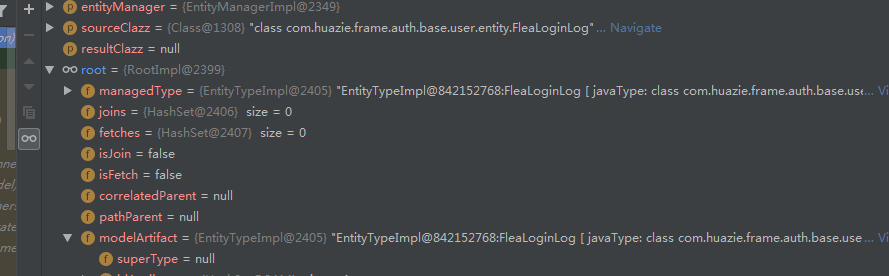
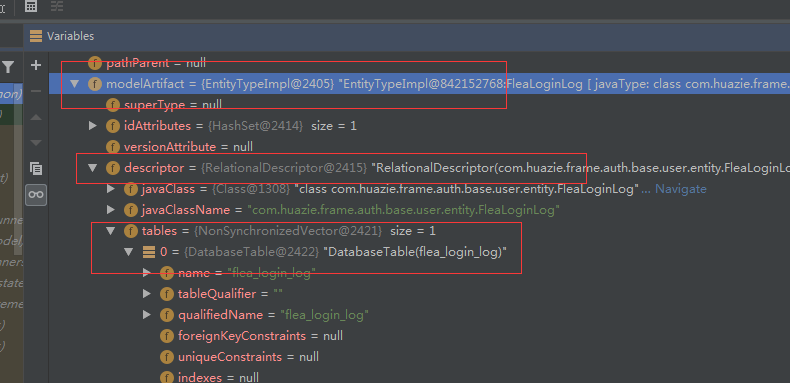
那么既然找到了表名实际相关的地方,下面的重点就是如何在使用的JPA标准化查询的过程中,动态改变查询的表名。
下面给出上述我们需要做的事情的解决方案:
2. 分表规则定义
实体类中定义的表名,我们可以理解为主表名;分表名的命名规则首先需要确定一下,定义如下配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| <?xml version="1.0" encoding="UTF-8"?>
<tables>
<table name="flea_login_log" exp="(FLEA_TABLE_NAME)_(CREATE_DATE)" desc="Flea登录日志表分表规则">
<splits>
<split key="yyyymm" column="create_date" implClass="com.huazie.frame.db.common.table.split.impl.YYYYMMTableSplitImpl"/>
</splits>
</table>
</tables>
|
分表规则相关实现代码,可以移步 GitHub 查看 TableSplitHelper
3. 分表查询实现
在上述分表规则定义中, 我们可以看到分表名表达式exp是由 主表名 和 分表字段 组成,分表字段的转换实现规则由split定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| @Override
public void handle(CriteriaQuery criteriaQuery, Object entity) throws Exception {
if (ObjectUtils.isEmpty(criteriaQuery) || ObjectUtils.isEmpty(entity)) {
return;
}
SplitTable splitTable = EntityUtils.getSplitTable(entity);
if (StringUtils.isNotBlank(splitTable.getSplitTableName())) {
Set<Root<?>> roots = criteriaQuery.getRoots();
if (CollectionUtils.isNotEmpty(roots)) {
((EntityTypeImpl<?>) roots.toArray(new Root<?>[0])[0].getModel()).getDescriptor().setTableName(splitTable.getSplitTableName());
}
}
}
|
JPA分表查询相关代码可以 移步 GitHub 查看 FleaJPAQuery 和 EclipseLinkTableSplitHandler;
4. 自测
自测类可以查看 AuthTest。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| @Test
public void testFleaLoginLog() {
try {
FleaLoginLog fleaLoginLog = new FleaLoginLog();
fleaLoginLog.setLoginIp4("127.0.0");
fleaLoginLog.setCreateDate(DateUtils.getCurrentTime());
FleaJPAQueryPool fleaJPAQueryPool = FleaObjectPoolFactory.getFleaObjectPool(FleaJPAQuery.class, FleaJPAQueryPool.class);
FleaJPAQuery query = fleaJPAQueryPool.getFleaObject();
LOGGER.debug("FleaJPAQuery: {}", query);
query.init(em, FleaLoginLog.class, null);
query.initQueryEntity(fleaLoginLog).distinct("accountId").like("loginIp4");
List<String> list = query.getSingleResultList();
LOGGER.debug("List : {}", list);
FleaJPAQuery query1 = fleaJPAQueryPool.getFleaObject();
LOGGER.debug("FleaJPAQuery: {}", query1);
query1.init(em, FleaLoginLog.class, null);
List<FleaLoginLog> fleaLoginLogList = query1.initQueryEntity(fleaLoginLog).getResultList();
LOGGER.debug("Resource List : {}", fleaLoginLogList);
} catch (Exception e) {
LOGGER.error("Exception:", e);
}
}
|
更新
这一版本存在并发的问题,目前已经重构,详见笔者后续的 flea-db使用之JPA分库分表实现,也可至GitHub查看笔者的 flea-framework中的 flea-db 模块。