
引言
本篇我们将逐步构建一个高效且可伸缩的缓存,用于改进一个高计算开销的函数。

主要内容
1. HashMap + 并发机制
我们首先能想到的就是,通过 HashMap 和并发机制来构建缓存,代码示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public interface Computable<A, V> {
V compute(A arg) throws InterruptedException;
}
public class ExpensiveFunction implements Computable<String, BigInteger> {
public BigInteger compute(String arg) {
return new BigInteger(arg);
}
}
public class Memoizer1<A, V> implements Computable<A, V> {
@GuardedBy("this")
private final Map<A, V> cache = new HashMap<A, V>();
private final Computable<A, V> c;
public Memoizer1(Computable<A, V> c) {
this.c = c;
}
public synchronized V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if (result == null) {
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}
|
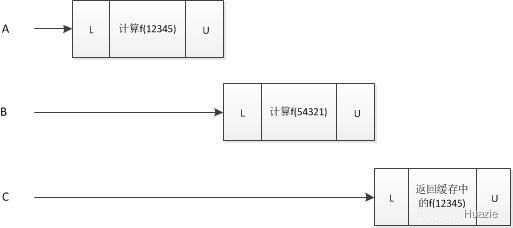
在上述 Memoizer1 中,我们使用 HashMap 来保存之前计算的结果。由于 HashMap 不是线程安全的,代码对整个 compute 方法进行同步。虽然这种方法能确保线程安全性,但每次只有一个线程能执行 compute 方法,其他线程可能就被阻塞很长时间,严重影响计算的并发性。如果有多个线程在排队等待还未计算的结果,那么 compute 方法的计算时间可能比没有缓存操作的计算时间更长,这显然不是我们想要看到的。
上述问题对应的错误的执行时序如下图所示:
2. ConcurrentHashMap
下面我们进一步改进下,在 Memoizer2 中,通过 ConcurrentHashMap 代替 HashMap 来构建缓存,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class Memoizer2<A, V> implements Computable<A, V> {
private final Map<A, V> cache = new ConcurrentHashMap<A, V>();
private final Computable<A, V> c;
public Memoizer2(Computable<A, V> c) {
this.c = c;
}
public V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if (result == null) {
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}
|
由于 ConcurrentHashMap 是线程安全的,因此在访问底层 Map 时就不需要进行同步了,相比 Memoizer1 而言,Memoizer2 有着更好的并发性。
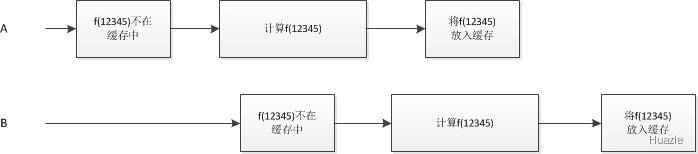
虽然多线程可以并发地使用 Memoizer2,但是它作为缓存来使用还是存在如下的问题:
- 当多个线程同时调用
compute 计算相同的数据时,由于计算数据和塞入缓存的操作并不是原子的,可能会导致重复计算。
- 当某个线程启动了很耗时的计算,而其他线程不论是不是同时启动,只要数据没有塞到缓存里,它们都是不知情的,那么也会导致重复计算。
上述问题对应的错误的执行时序如下图所示:
对于计算相同的数据,我们更希望线程 X 正在计算 f(12345),而其他线程在计算 f(12345) 时,它们能够等待线程 X 计算结束,然后去查询缓存 f(12345) 的结果。
看过笔者前面的博文,相信大家很容易想到并发工具类中的 FutureTask 可以实现上面的效果。
回顾:FutureTask 表示一个计算的过程,这个过程可能已经计算完成,也可能正在进行。如果有结果可用,那么 FutureTask.get 将立即返回结果,否则它会一直阻塞,直到结果计算出来再将其返回。
3. ConcurrentHashMap + Future
下面我们再一次改进下,在 Memoizer3 中,将用于缓存值的 Map 重新定义为 ConcurrentHashMap<A, Future<V>>,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public class Memoizer3<A, V> implements Computable<A, V> {
private final Map<A, Future<V>> cache = new ConcurrentHashMap<>();
private final Computable<A, V> c;
public Memoizer3(Computable<A, V> c) {
this.c = c;
}
public V compute(A arg) throws InterruptedException {
Future<V> future = cache.get(arg);
if (future == null) {
Callable<V> eval = new Callable<V>() {
public V call() throws InterruptedException {
return c.compute(arg);
}
};
FutureTask<V> futureTask = new FutureTask<V>(eval);
future = futureTask;
cache.put(arg, futureTask);
futureTask.run();
}
try {
return future.get();
} catch (ExecutionException e) {
throw ExceptionUtils.launderThrowable(e.getCause());
}
}
}
|
上述示例 Memoizer3 首先检查某个相应的计算是否已经开始。如果还没有启动,那么就创建一个 FutureTask,并注册到 Map 中,然后启动计算;如果已经启动,那么等待现有计算的结果。
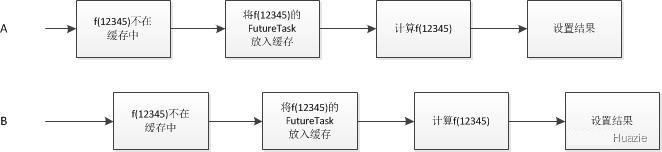
到目前为止,Memoizer3 在上述三个方案中属于最优方案。但它仍然存在多个线程计算出相同值的情况:由于 compute 方法中的 if 代码块是非原子的 “先检查再执行” 操作,因而两个线程仍有可能在同一时间内调用 compute 来计算相同的值。
上述问题对应的错误的执行时序如下图所示:
4. ConcurrentHashMap + Future 改进版
接下来我们继续改进下,在 Memoizer 中,使用 ConcurrentHashMap 中的原子方法 putIfAbsent,来避免 Memoizer3 中的问题,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| public class Memoizer<A, V> implements Computable<A, V> {
private final Map<A, Future<V>> cache = new ConcurrentHashMap<>();
private final Computable<A, V> c;
public Memoizer(Computable<A, V> c) {
this.c = c;
}
public V compute(A arg) throws InterruptedException {
while (true) {
Future<V> future = cache.get(arg);
if (future == null) {
Callable<V> eval = new Callable<V>() {
public V call() throws InterruptedException {
return c.compute(arg);
}
};
FutureTask<V> futureTask = new FutureTask<V>(eval);
future = cache.putIfAbsent(arg, futureTask);
if (future == null) {
future = futureTask;
futureTask.run();
}
}
try {
return future.get();
} catch (CancellationException e) {
cache.remove(arg, future);
} catch (RuntimeException e) {
cache.remove(arg, future);
} catch (ExecutionException e) {
throw launderThrowable(e.getCause());
}
}
}
}
|
当然,作为一个高效且可伸缩的缓存来讲,Memoizer 依然有如下的问题:
- 缓存逾期问题【即缓存过期移除,可以通过
FutureTask 的子类实现,在子类中为每个结果指定一个逾期时间,并定期扫描缓存中逾期的元素,然后将其移除】
- 缓存清理问题【即移除旧的计算结果以便为新的计算结果腾出空间,从而使缓存不会消耗过多的内存】
5. 因式分解Servlet应用结果缓存
到目前为止,Memoizer 已经能够很好地满足高计算开销函数的要求。下面我们来为《线程安全性》的博文中提到的因式分解 Servlet 添加结果缓存,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class Factorizer extends HttpServlet {
private final Computable<BigInteger, BigInteger[]> c = new Computable<BigInteger, BigInteger[]>() {
public BigInteger[] compute(BigInteger arg) {
return Factor.factor(arg);
}
};
private final Computable<BigInteger, BigInteger[]> cache = new Memoizer<>(c);
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException {
try {
BigInteger i = CommonUtils.extractFromRequest(req);
CommonUtils.encodeIntoResponse(resp, cache.compute(i));
} catch (InterruptedException e) {
CommonUtils.encodeError(resp, "factorization interrupted");
}
}
}
|
示例
本篇所有示例代码地址 请点击这里,其中的 Servlet 可以通过 JettyStarter 启动服务端,然后浏览器访问 http://localhost:8080/memoizer?factor=1231231234 或者 使用 JMeter 模拟多用户高并发请求。
总结
本篇演示了如何通过前面学到的并发基础构建模块,来逐步构建一个 “高效且可伸缩” 的结果缓存,一定程度上能够为我们设计和开发并发应用程序带来一些思考。