![]()
引言
前面的章节介绍了任务执行框架及其实际应用的一些内容。
本篇开始将分析在使用任务执行框架时需要注意的各种情况,并介绍对线程池进行配置与调优的一些方法。
![]()
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcsdup(const wchar_t *str); |
用于复制宽字符字符串 |
int wcsicmp(const wchar_t *s1, const wchar_t *s2); |
用于比较两个宽字符字符串的大小写不敏感的差异 |
int wcsicoll(const wchar_t *s1, const wchar_t *s2); |
用于比较两个宽字符字符串的大小写不敏感的差异, 并考虑当前本地环境的语言和排序规则 |
wchar_t *wcslwr(wchar_t *str); |
用于将宽字符字符串转换为小写字母形式 |
wchar_t *wcspbrk(const wchar_t *str, const wchar_t *charset); |
用于在宽字符字符串中查找指定字符集中任意一个字符第一次出现的位置 |
int wcsnicmp(const wchar_t *s1, const wchar_t *s2, size_t n); |
用于比较两个宽字符字符串的前若干个字符的大小写不敏感的差异 |
wchar_t *wcsnset(wchar_t *str, wchar_t ch, size_t n); |
用于将宽字符字符串中的前若干个字符设置为指定字符 |
wchar_t *wcsrev(wchar_t *str); |
用于将宽字符字符串反转 |
wchar_t *wcsset(wchar_t *str, wchar_t ch); |
用于将宽字符字符串中的所有字符设置为指定字符 |
long int wcstoll(const wchar_t* str, wchar_t** endptr, int base); |
用于将宽字符串转换为长整形 |
unsigned long long int wcstoull(const wchar_t* str, wchar_t** endptr, int base); |
用于将宽字符串转换为无符号长整型 |
wchar_t* wcsupr(wchar_t* str); |
用于将宽字符串转换为大写 |
wctrans_t wctrans(const char* property); |
用于创建字符转换描述符 |
wchar_t* wmempcpy(wchar_t* dest, const wchar_t* src, size_t n); |
用于将将源宽字符串的前 n 个字节的内容拷贝到目标字符串中 |
wchar_t* wmemmove(wchar_t* dest, const wchar_t* src, size_t n); |
将源宽字符串中指定数量的字节复制到目标宽字符串中,即使目标内存和源内存重叠 |
| 函数声明 | 函数功能 |
|---|---|
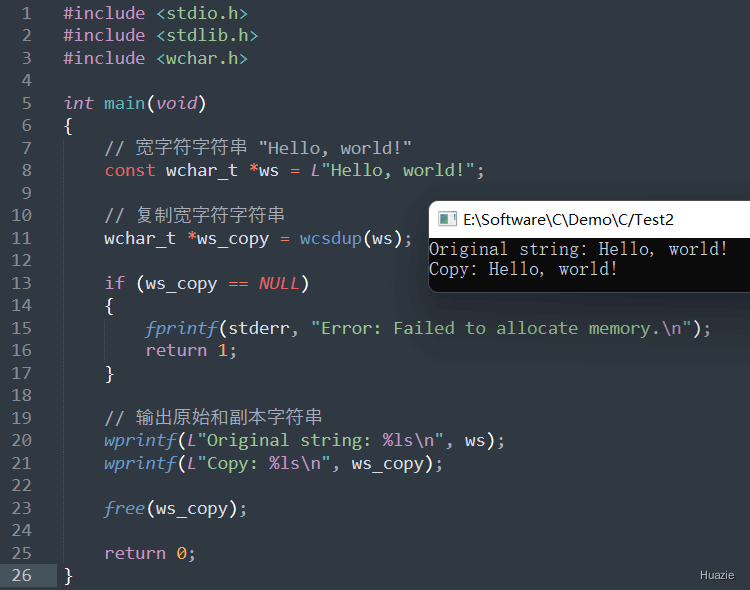
wchar_t *wcsdup(const wchar_t *str); |
用于复制宽字符字符串 |
参数:
返回值:
NULL。1 |
|
| 函数声明 | 函数功能 |
|---|---|
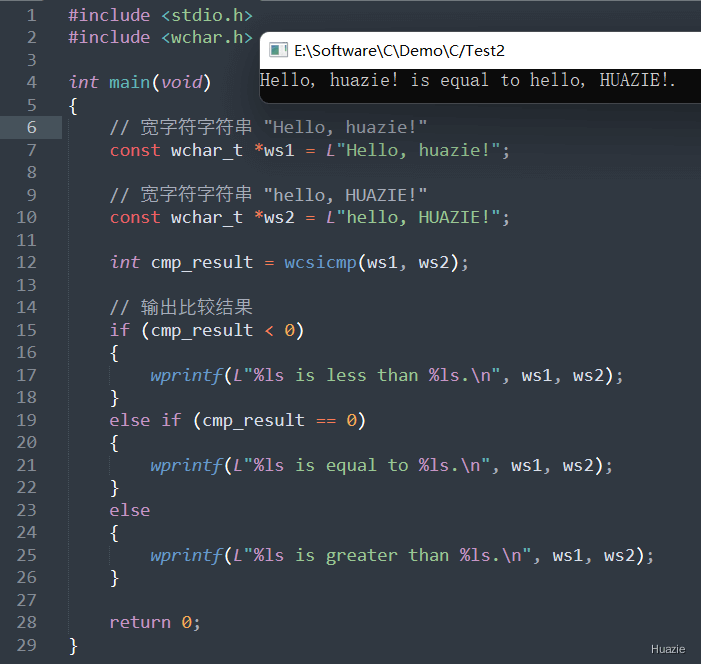
int wcsicmp(const wchar_t *s1, const wchar_t *s2); |
用于比较两个宽字符字符串的大小写不敏感的差异 |
参数:
返回值:
s1 指向的字符串按字典顺序小于 s2 指向的字符串(忽略大小写),则函数返回一个负整数;s1 等于 s2,则函数返回 0;s1 指向的字符串按字典顺序大于 s2 指向的字符串(忽略大小写),则函数返回一个正整数。1 |
|
| 函数声明 | 函数功能 |
|---|---|
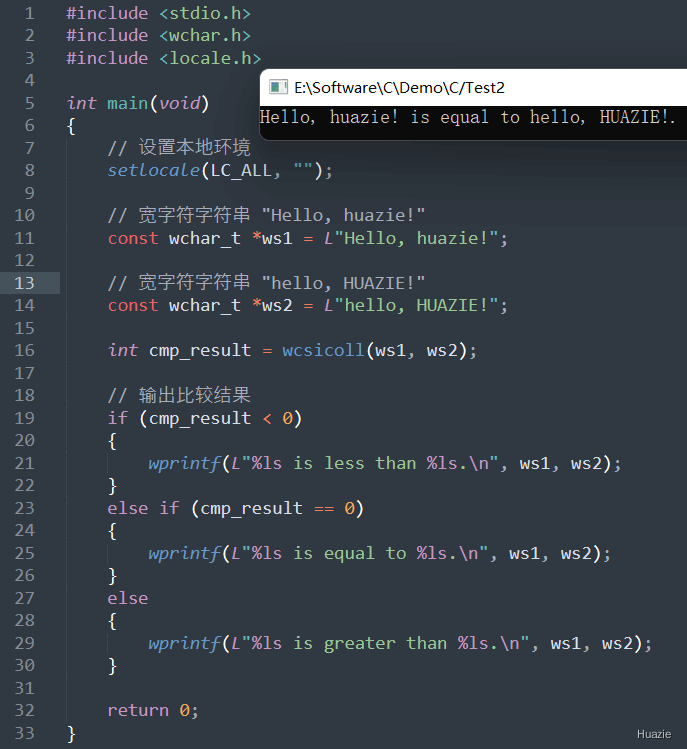
int wcsicoll(const wchar_t *s1, const wchar_t *s2); |
用于比较两个宽字符字符串的大小写不敏感的差异, 并考虑当前本地环境的语言和排序规则 |
参数:
返回值:
s1 指向的字符串按字典顺序小于 s2 指向的字符串(忽略大小写),则函数返回一个负整数;s1 等于 s2,则函数返回 0;s1 指向的字符串按字典顺序大于 s2 指向的字符串(忽略大小写),则函数返回一个正整数。1 |
|
注意: 在使用 wcsicoll() 函数前,需要先调用 setlocale() 函数设置本地环境。
| 函数声明 | 函数功能 |
|---|---|
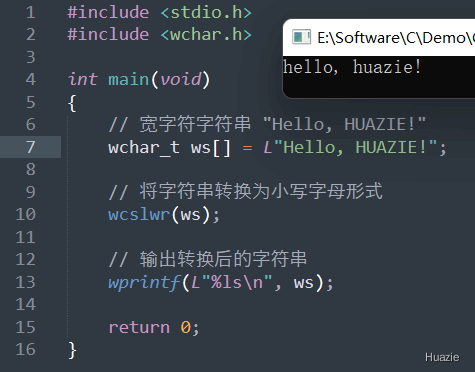
wchar_t *wcslwr(wchar_t *str); |
用于将宽字符字符串转换为小写字母形式 |
参数:
1 |
|
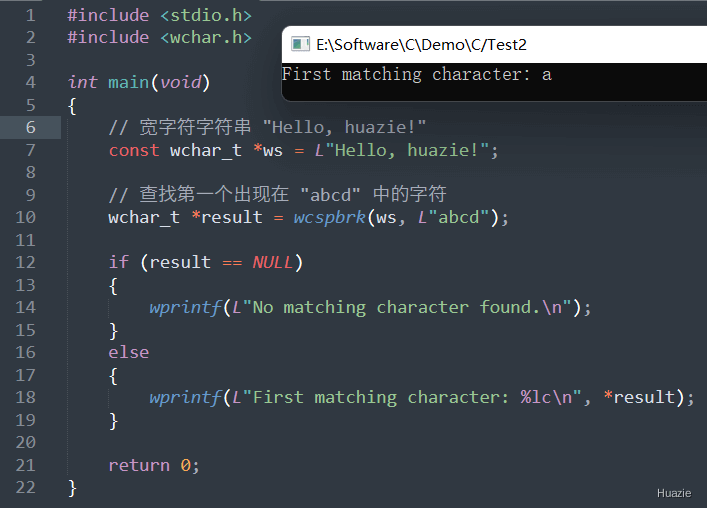
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcspbrk(const wchar_t *str, const wchar_t *charset); |
用于在宽字符字符串中查找指定字符集中任意一个字符第一次出现的位置 |
参数:
wcspbrk() 函数会将 str 指向的宽字符字符串中的每个字符与 charset 指向的宽字符集合中的字符进行比较,直到找到其中任意一个相同的字符为止。
返回值:
NULL。1 |
|
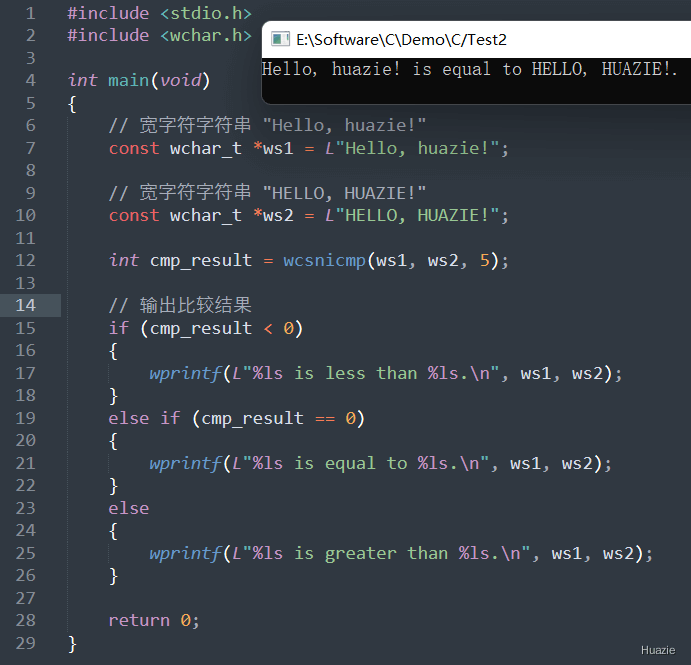
| 函数声明 | 函数功能 |
|---|---|
int wcsnicmp(const wchar_t *s1, const wchar_t *s2, size_t n); |
用于比较两个宽字符字符串的前若干个字符的大小写不敏感的差异 |
参数:
返回值:
s1 指向的字符串按字典顺序小于 s2 指向的字符串(忽略大小写),则函数返回一个负整数;s1 等于 s2,则函数返回 0;s1 指向的字符串按字典顺序大于 s2 指向的字符串(忽略大小写),则函数返回一个正整数。1 |
|
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcsnset(wchar_t *str, wchar_t ch, size_t n); |
用于将宽字符字符串中的前若干个字符设置为指定字符 |
参数:
1 |
|

| 函数声明 | 函数功能 |
|---|---|
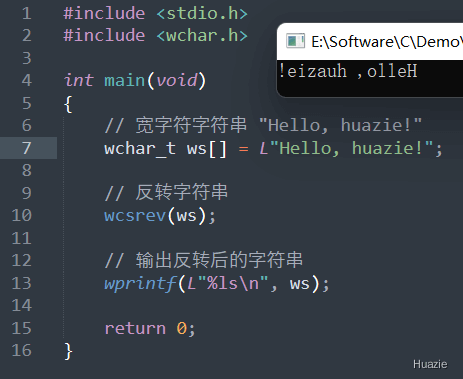
wchar_t *wcsrev(wchar_t *str); |
用于将宽字符字符串反转 |
参数:
1 |
|
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcsset(wchar_t *str, wchar_t ch); |
用于将宽字符字符串中的所有字符设置为指定字符 |
参数:
1 |
|
注意: wcsset() 函数会修改原始字符串,因此需要在操作前确保原始字符串可以被修改。
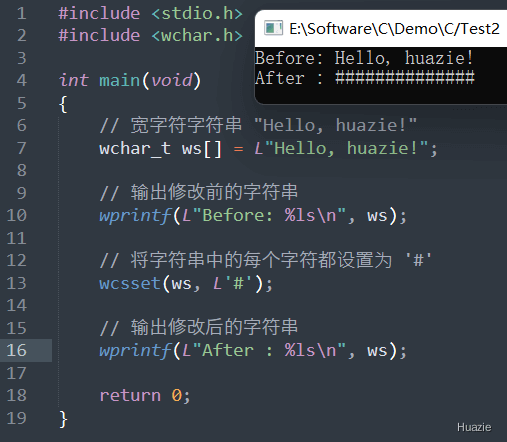
| 函数声明 | 函数功能 |
|---|---|
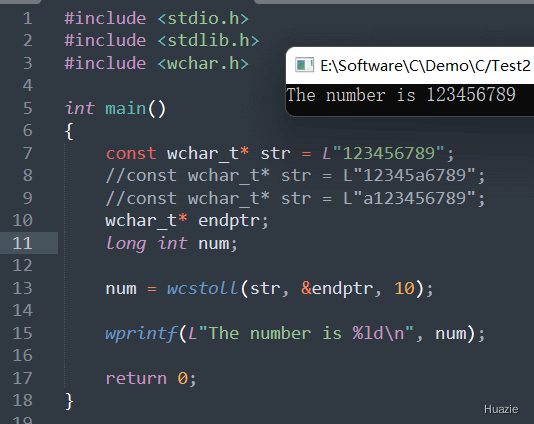
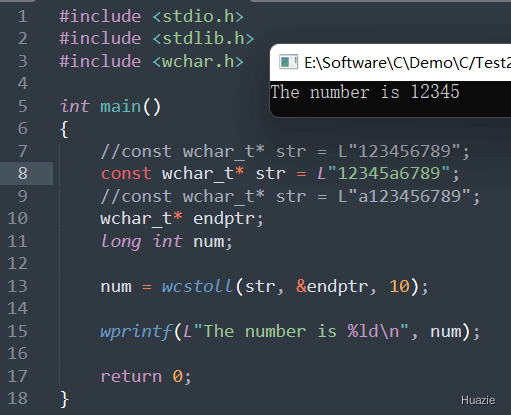
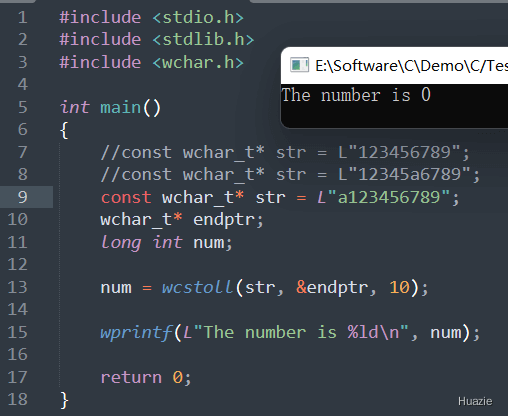
long int wcstoll(const wchar_t* str, wchar_t** endptr, int base); |
用于将宽字符串转换为长整形 |
参数:
nullptr 时,不会返回无法被识别的宽字符位置1 |
|
| 函数声明 | 函数功能 |
|---|---|
unsigned long long int wcstoull(const wchar_t* str, wchar_t** endptr, int base); |
用于将宽字符串转换为无符号长整型 |
参数:
nullptr 时,不会返回无法被识别的宽字符位置1 |
|
wcstoull() 函数的用法和 wcstoll() 函数类似,不再赘述了。
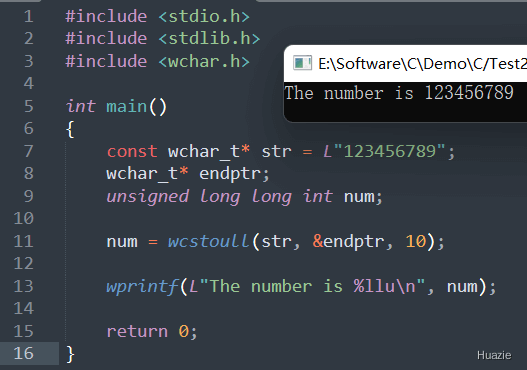
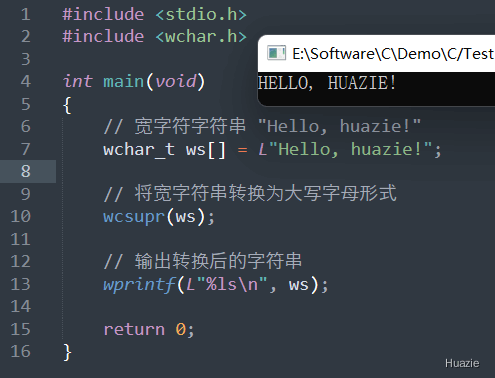
| 函数声明 | 函数功能 |
|---|---|
wchar_t* wcsupr(wchar_t* str); |
用于将宽字符串转换为大写 |
参数:
1 |
|
| 函数声明 | 函数功能 |
|---|---|
wctrans_t wctrans(const char* property); |
用于创建字符转换描述符 |
wint_t towctrans(wint_t wc, wctrans_t desc); |
通过 wctrans() 函数创建的字符转换描述符,可以将一个字符或字符串进行指定类型的转换。 |
wctrans 参数:
towctrans 参数:
1 |
|
![]()
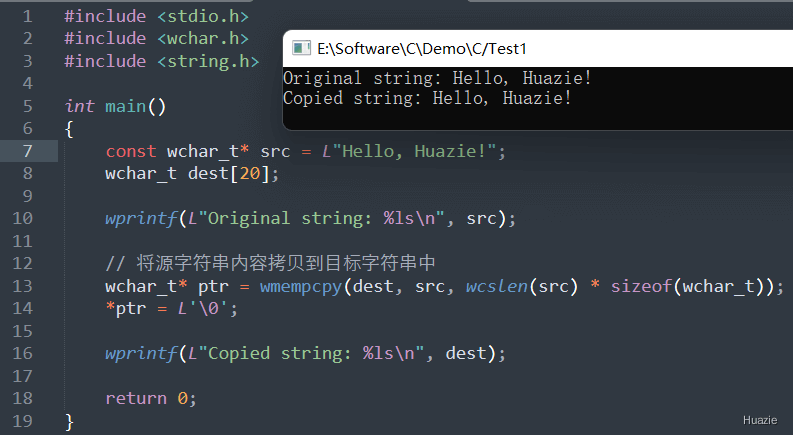
| 函数声明 | 函数功能 |
|---|---|
wchar_t* wmempcpy(wchar_t* dest, const wchar_t* src, size_t n); |
用于将将源宽字符串的前 n 个字节的内容拷贝到目标字符串中 |
参数:
1 |
|
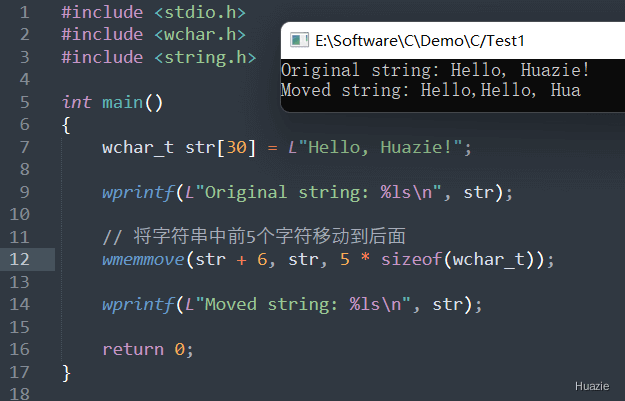
| 函数声明 | 函数功能 |
|---|---|
wchar_t* wmemmove(wchar_t* dest, const wchar_t* src, size_t n); |
将源宽字符串中指定数量的字节复制到目标宽字符串中,即使目标内存和源内存重叠 |
参数:
1 |
|
![]()
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim, wchar_t **ptr); |
用于将一个长字符串拆分成几个短字符串(标记),并返回第一个标记的地址 |
wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim); |
用于将一个长字符串拆分成几个短字符串(标记),并返回第一个标记的地址 |
long int wcstol(const wchar_t* str, wchar_t** endptr, int base); |
用于将字符串转换为长整型数字的函数 |
unsigned long int wcstoul(const wchar_t* str, wchar_t** endptr, int base); |
用于将字符串转换为无符号长整型数字 |
size_t wcsxfrm(wchar_t* dest, const wchar_t* src, size_t n); |
将一个 Unicode 字符串转换为一个 “可排序” 的字符串。该新字符串中的字符序列反映了源字符串中的字符顺序和大小写信息,以便进行字典序比较。 |
wctype_t wctype(const char* property); |
用于确定给定的宽字符类别 |
int wctob(wint_t wc); |
用于将给定的宽字符转换为其对应的字节表示 |
int wctomb(char* s, wchar_t wc); |
用于将给定的宽字符转换为其对应的多字节字符表示 |
void* wmemchr(const void* s, wchar_t c, size_t n); |
用于在宽字符数组中查找给定的宽字符 |
int wmemcmp(const wchar_t* s1, const wchar_t* s2, size_t n); |
用于比较两个宽字符数组的前 n 个宽字符 |
wchar_t* wmemcpy(wchar_t* dest, const wchar_t* src, size_t n); |
用于将一个宽字符数组的前 n 个宽字符复制到另一个宽字符数组 |
wchar_t* wmemset(wchar_t* s, wchar_t c, size_t n); |
用于将一个宽字符数组的前 n 个宽字符设置为给定的宽字符值 |
int wprintf(const wchar_t* format, ...); |
用于格式化输出宽字符字符串 |
ssize_t write(int fd, const void* buf, size_t count); |
用于将数据写入文件描述符 |
int wscanf(const wchar_t* format, ...); |
用于从标准输入流(stdin)读取格式化的宽字符输入 |
| 函数声明 | 函数功能 |
|---|---|
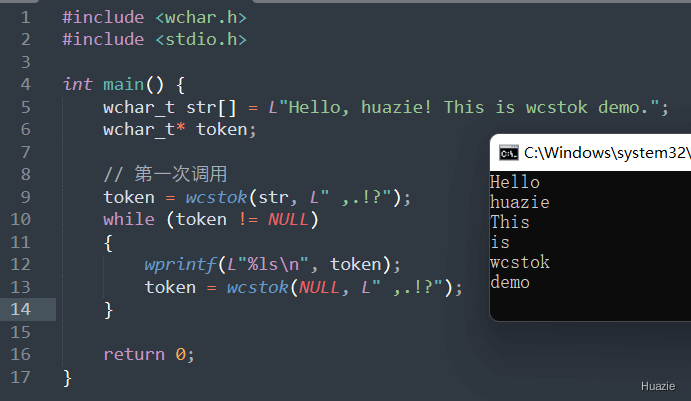
wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim, wchar_t **ptr); |
用于将一个长字符串拆分成几个短字符串(标记),并返回第一个标记的地址 |
wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim); |
用于将一个长字符串拆分成几个短字符串(标记),并返回第一个标记的地址 |

参数:
NULLwindows 下两个参数的示例:
1 |
|
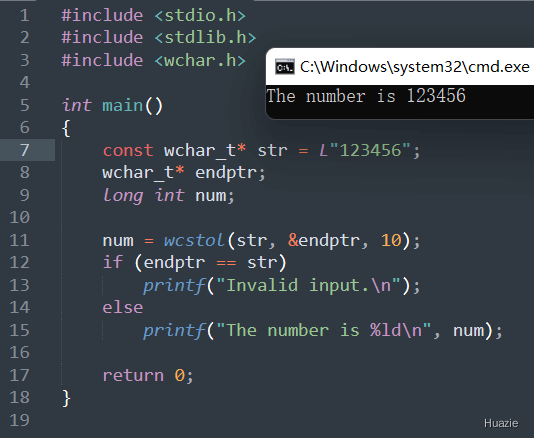
| 函数声明 | 函数功能 |
|---|---|
long int wcstol(const wchar_t* str, wchar_t** endptr, int base); |
用于将字符串转换为长整型数字的函数 |
参数:
2 和 36 之间;base 参数为 0 时,wcstol() 函数会自动检测数字基数:"0x" 或 "0X" 开头,则将基数设置为 16。"0" 开头,则将基数设置为 8。10。1 |
|
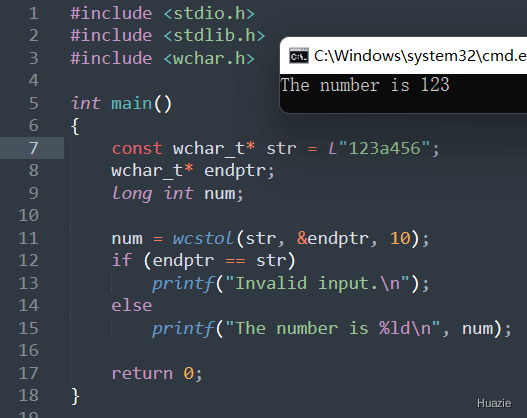
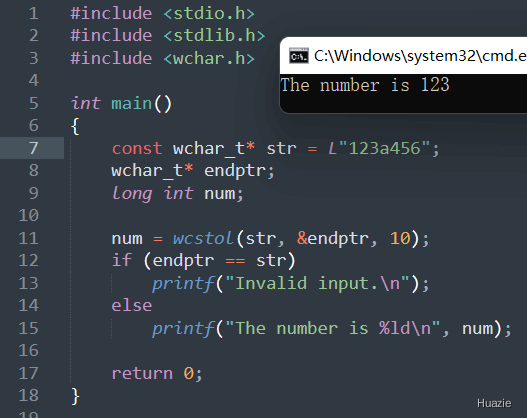
注意: 如果输入字符串无法转换为数字,则 wcstol() 函数返回 0,并将 endptr 指向输入字符串的起始位置。所以,在使用 wcstol() 函数时,建议检查 endptr 和 str 是否相同,以确定输入是否有效。
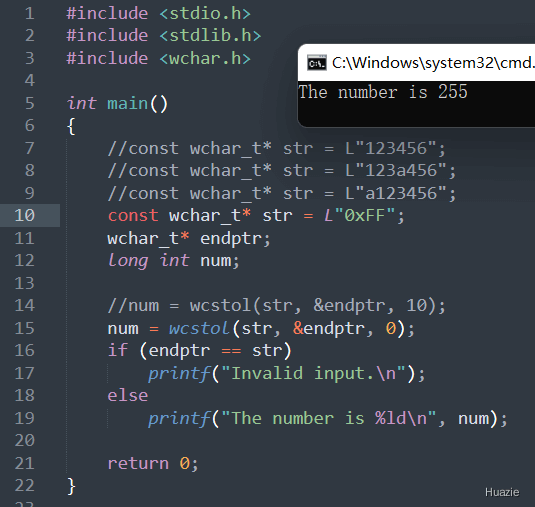
| 函数声明 | 函数功能 |
|---|---|
unsigned long int wcstoul(const wchar_t* str, wchar_t** endptr, int base); |
用于将字符串转换为无符号长整型数字 |
参数:
2 和 36 之间;base 参数为 0 时,wcstol() 函数会自动检测数字基数:"0x" 或 "0X" 开头,则将基数设置为 16。"0" 开头,则将基数设置为 8。10。1 |
|
wcstoul() 函数的用法和 wcstol() 函数类似,这里就不一一列举了
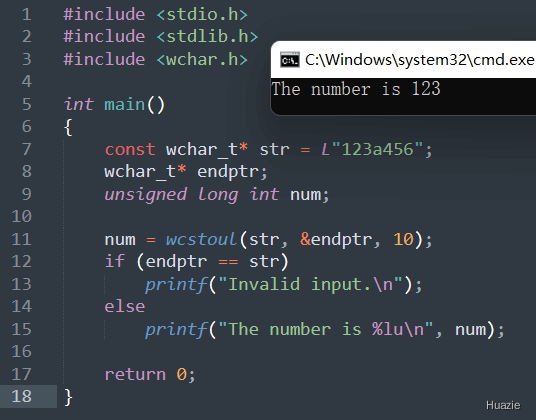
| 函数声明 | 函数功能 |
|---|---|
size_t wcsxfrm(wchar_t* dest, const wchar_t* src, size_t n); |
将一个 Unicode 字符串转换为一个 “可排序” 的字符串。该新字符串中的字符序列反映了源字符串中的字符顺序和大小写信息,以便进行字典序比较。 |
参数:
1 |
|
在上面的示例代码中,
5 个 Unicode 字符串的字符串数组 arr,每个字符串代表一个人名;5x50 的二维字符数组 sorted_arr,用于存储排序后的字符串;wcsxfrm() 函数将每个 Unicode 字符串转换为可排序字符串,并将结果存储在 sorted_arr 数组中;qsort() 函数按字典序对 sorted_arr 数组中的字符串进行排序;wprintf() 函数输出排序后的字符串;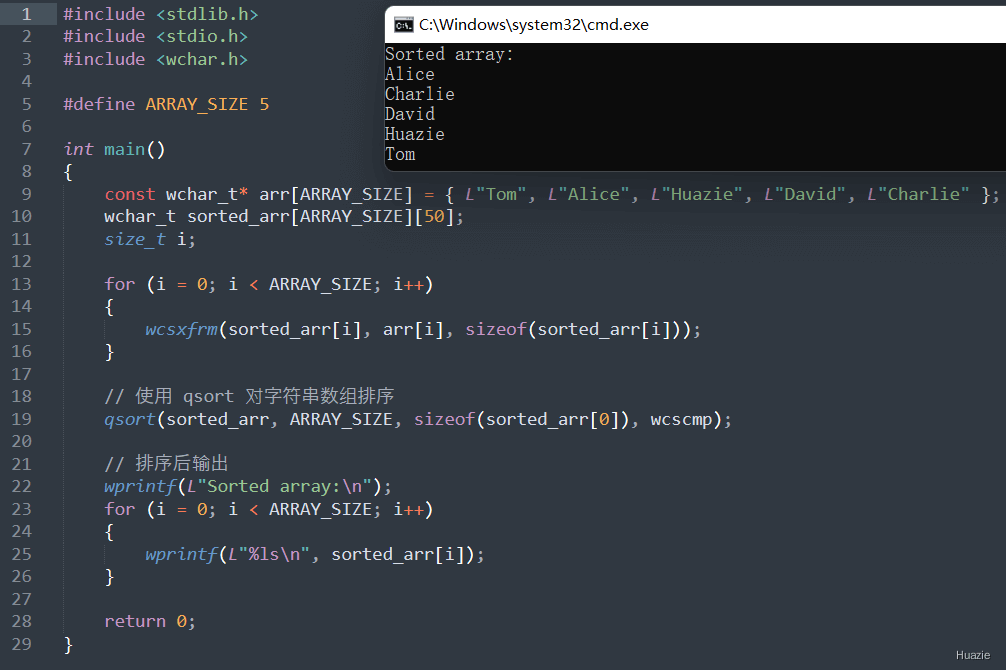
| 函数声明 | 函数功能 |
|---|---|
wctype_t wctype(const char* property); |
用于确定给定的宽字符类别 |
参数:
常见的宽字符属性及含义如下:
| 属性名称 | 含义 |
|---|---|
"alnum" |
字母数字字符 |
"alpha" |
字母字符 |
"blank" |
空格或水平制表符字符 |
"cntrl" |
控制字符 |
"digit" |
数字字符 |
"graph" |
可打印字符(除空格字符外) |
"lower" |
小写字母字符 |
"print" |
可打印字符 |
"punct" |
标点符号字符 |
"space" |
空白字符 |
"upper" |
大写字母字符 |
"xdigit" |
十六进制数字字符 |
返回值:
1 |
|
注意: 在调用 wctype() 函数时,应该传递一个有效的宽字符属性名称作为参数,详见 5.1 的表格所示。
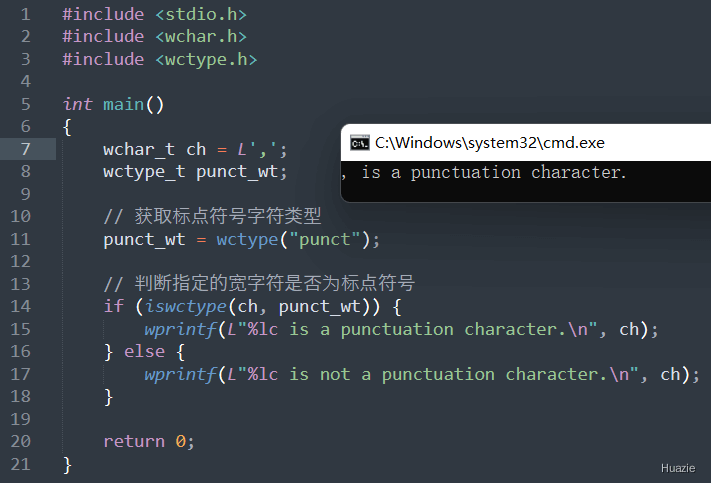
| 函数声明 | 函数功能 |
|---|---|
int wctob(wint_t wc); |
用于将给定的宽字符转换为其对应的字节表示 |
参数:
返回值:
EOF。1 |
|
注意: 在使用 wctob() 函数时,应该确保系统当前的本地化环境和编码方式与程序中使用的字符编码一致。如果字符编码不一致,可能会导致错误的结果或未定义行为。
| 函数声明 | 函数功能 |
|---|---|
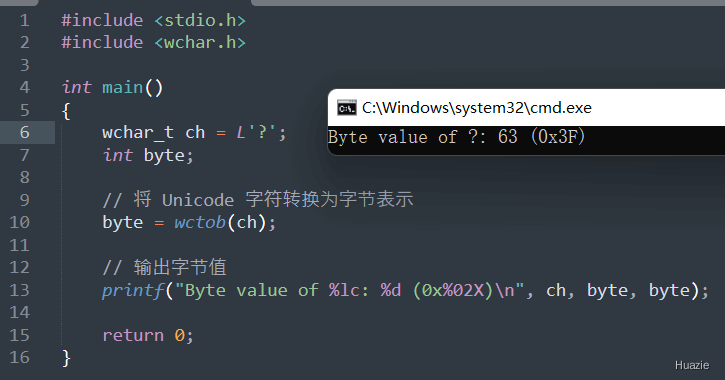
int wctomb(char* s, wchar_t wc); |
用于将给定的宽字符转换为其对应的多字节字符表示 |
参数:
返回值:
wc 转换为其对应的多字节字符表示,存储在 s 指向的字符数组中;s 是空指针,则不执行任何操作,只返回转换所需的字符数;-1。1 |
|
在上面的示例程序中,wctomb() 函数被用来将 Unicode 字符 ',' 转换为其对应的多字节字符表示,并将结果保存在字符数组 mb 中。然后,程序输出每个字节的十六进制值。
注意: 在使用 wctomb() 函数时,应该根据当前的本地化环境和编码方式调整字符数组的大小。可以使用 MB_CUR_MAX 宏来获取当前编码方式下一个多字节字符所需的最大字节数,从而确定字符数组的大小。
| 函数声明 | 函数功能 |
|---|---|
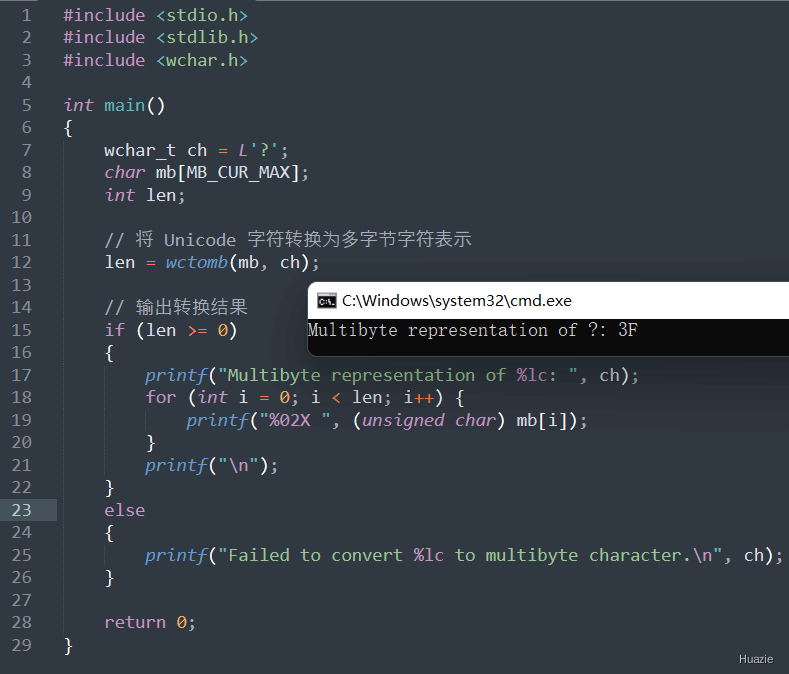
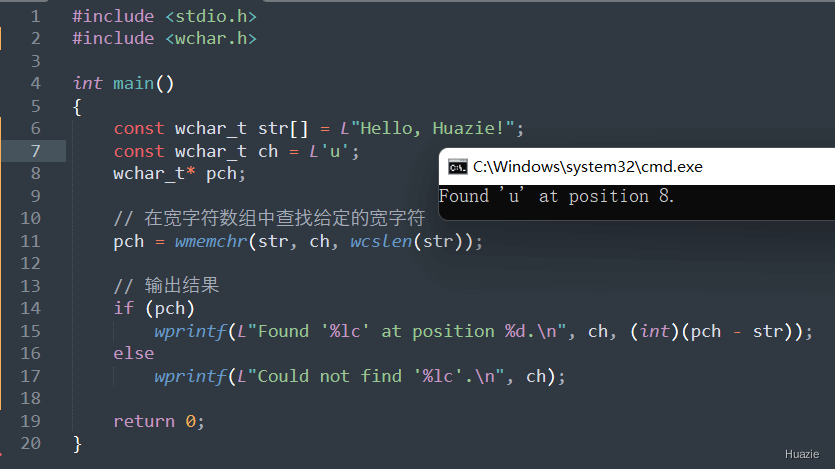
void* wmemchr(const void* s, wchar_t c, size_t n); |
用于在宽字符数组中查找给定的宽字符 |
参数:
返回值:
c,则返回指向该位置的指针;1 |
|
| 函数声明 | 函数功能 |
|---|---|
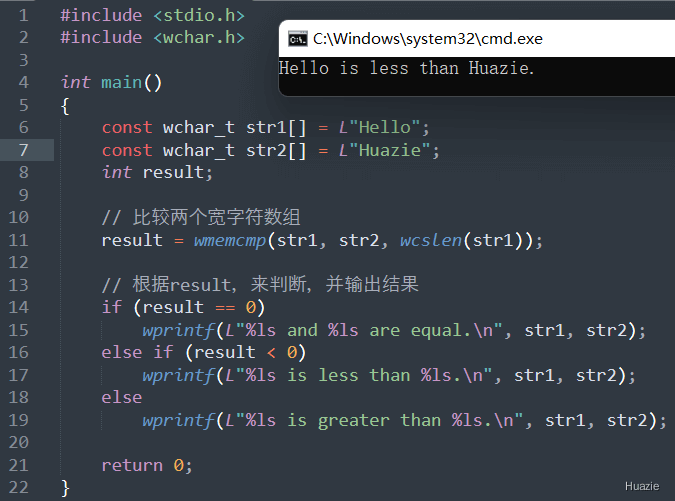
int wmemcmp(const wchar_t* s1, const wchar_t* s2, size_t n); |
用于比较两个宽字符数组的前 n 个宽字符 |
参数:
返回值:
s1 比 s2 小,则返回负数;s1 比 s2 大,则返回正数。1 |
|
| 函数声明 | 函数功能 |
|---|---|
wchar_t* wmemcpy(wchar_t* dest, const wchar_t* src, size_t n); |
用于将一个宽字符数组的前 n 个宽字符复制到另一个宽字符数组 |
参数:
1 |
|
注意: 在使用 wmemcpy() 函数时,应该确保目标数组有足够的空间来存储源数组的内容,以免发生缓冲区溢出。在上面的示例中,我们使用 wcslen() 函数来获取源数组的长度,然后加上 1,以包括字符串结尾的空字符 '\0'。
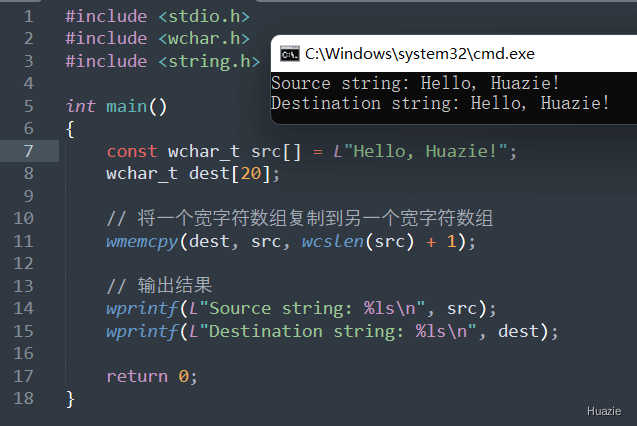
| 函数声明 | 函数功能 |
|---|---|
wchar_t* wmemset(wchar_t* s, wchar_t c, size_t n); |
用于将一个宽字符数组的前 n 个宽字符设置为给定的宽字符值 |
参数:
1 |
|
在上面的示例程序中,
"Hello Huazie!";wprintf() 函数输出修改之前的宽字符数组 str;wmemset() 函数将宽字符数组 str 的所有元素都设置为 ‘X’;wprintf() 函数输出修改之后的宽字符数组 str,并结束程序。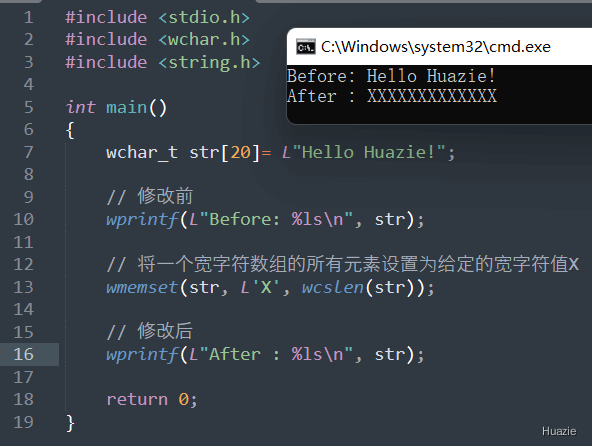
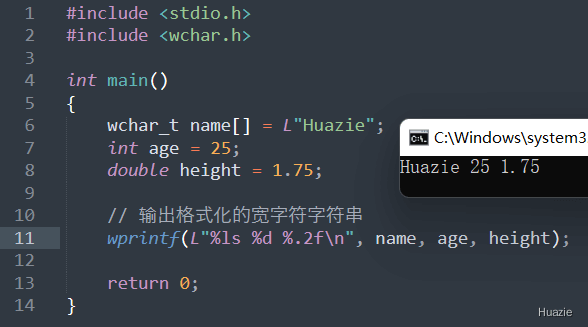
| 函数声明 | 函数功能 |
|---|---|
int wprintf(const wchar_t* format, ...); |
用于格式化输出宽字符字符串 |
参数:
1 |
|
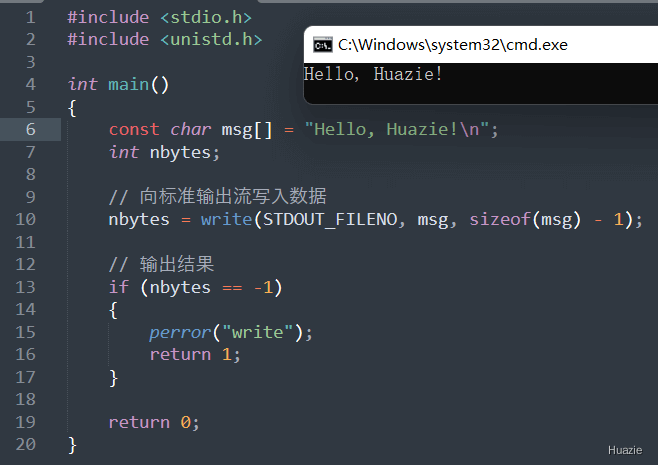
| 函数声明 | 函数功能 |
|---|---|
ssize_t write(int fd, const void* buf, size_t count); |
用于将数据写入文件描述符 |
参数:
返回值:
-1。1 |
|
注意: 在使用 write() 函数时,应该确保给定的文件描述符是有效的,并且缓冲区中有足够的数据可供写入,以免发生未定义的行为
| 函数声明 | 函数功能 |
|---|---|
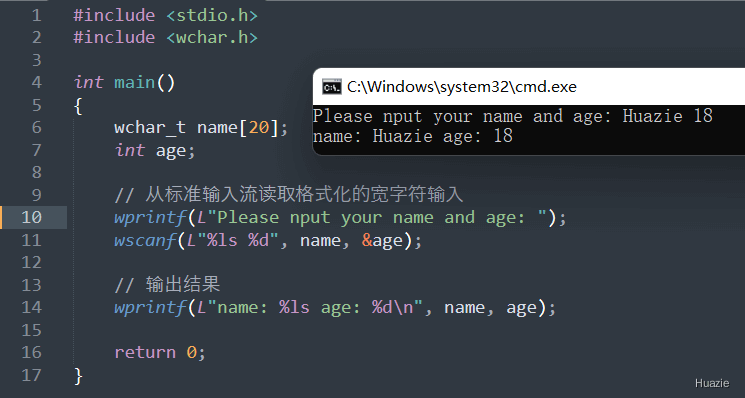
int wscanf(const wchar_t* format, ...); |
用于从标准输入流(stdin)读取格式化的宽字符输入 |
参数:
1 |
|
![]()
| 函数声明 | 函数功能 |
|---|---|
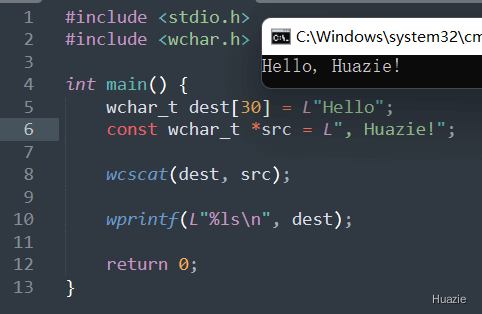
wchar_t * wcscat(wchar_t *dest, const wchar_t *src); |
用于将一个宽字符字符串追加到另一个宽字符字符串的末尾 |
wchar_t *wcschr(const wchar_t *str, wchar_t wc); |
用于在宽字符串中查找指定字符的位置 |
int wcscmp(const wchar_t *str1, const wchar_t *str2); |
用于比较两个宽字符串的大小;它将两个字符串逐个字符进行比较,直到遇到不同的字符或者其中一个字符串结束为止 |
int wcscoll(const wchar_t *str1, const wchar_t *str2); |
用于比较两个宽字符串的大小 |
wchar_t *wcscpy(wchar_t *dest, const wchar_t *src); |
用于将一个宽字符串复制到另一个字符串中 |
size_t wcsftime(wchar_t *str, size_t maxsize, const wchar_t *format, const struct tm *timeptr); |
用于将日期和时间格式化为宽字符字符串 |
size_t wcslen(const wchar_t *str); |
用于计算宽字符串的长度 |
wchar_t *wcsncat(wchar_t *dest, const wchar_t *src, size_t n); |
用于将一个宽字符串的一部分追加到另一个宽字符串末尾 |
int wcsncmp(const wchar_t *str1, const wchar_t *str2, size_t n); |
用于比较两个宽字符串的前若干个字符是否相同 |
wchar_t *wcsncpy(wchar_t *dest, const wchar_t *src, size_t n); |
用于将一个宽字符串的一部分复制到另一个宽字符串中 |
size_t wcsrtombs(char *dest, const wchar_t **src, size_t n, mbstate_t *ps); |
用于将宽字符串转换为多字节字符串 |
wchar_t *wcsstr(const wchar_t *haystack, const wchar_t *needle); |
用于在一个宽字符串中查找另一个宽字符串 |
size_t wcsspn(const wchar_t *str, const wchar_t *accept); |
用于查找宽字符串中连续包含某些字符集合中的字符的最长前缀 |
double wcstod(const wchar_t *nptr, wchar_t **endptr); |
用于将宽字符串转换为双精度浮点数 |
| 函数声明 | 函数功能 |
|---|---|
wchar_t * wcscat(wchar_t *dest, const wchar_t *src); |
用于将一个宽字符字符串追加到另一个宽字符字符串的末尾 |
参数:
1 |
|
在上面的示例代码中,
30 的 wchar_t 数组 dest,并初始化为 "Hello";src,指向字符串 ", Huazie!";wcscat() 函数将 src 字符串中的所有字符追加到 dest 字符串的末尾,形成新的宽字符字符串 "Hello, Huazie!";wprintf() 函数将新的字符串输出到控制台。注意: 在使用 wcscat() 函数时,需要确保目标字符串 dest 的空间足够大,以容纳源字符串 src 的所有字符和一个结束符(\0)。如果目标字符串的空间不足,可能会导致数据覆盖和未定义行为。
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcschr(const wchar_t *str, wchar_t wc); |
用于在宽字符串中查找指定字符的位置 |
参数:
返回值:
str 字符串中查找到第一个与 wc 相等的宽字符,则返回该字符在字符串中的地址;1 |
|
在上面的示例代码中,
str,并初始化为 "hello, huazie";c,值为 'u';wcschr() 函数在 str 字符串中查找字符 c,并将返回结果保存在指针变量 p 中;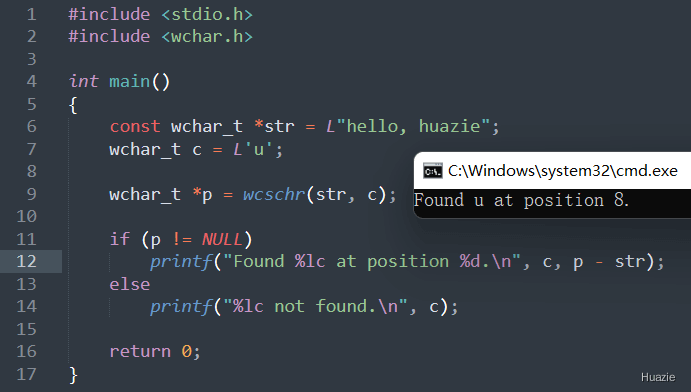
| 函数声明 | 函数功能 |
|---|---|
int wcscmp(const wchar_t *str1, const wchar_t *str2); |
用于比较两个宽字符串的大小;它将两个字符串逐个字符进行比较,直到遇到不同的字符或者其中一个字符串结束为止 |
参数:
返回值:
str1 小于 str2,则返回一个负整数;str1 等于 str2,则返回 0;str1 大于 str2,则返回一个正整数。1 |
|
在上述的示例代码中,
str1 和 str2,分别初始化为 "hello" 和 "huazie";wcscmp() 函数比较两个字符串的大小,并将返回结果保存在变量 result 中;result 的值,输出相应的比较结果;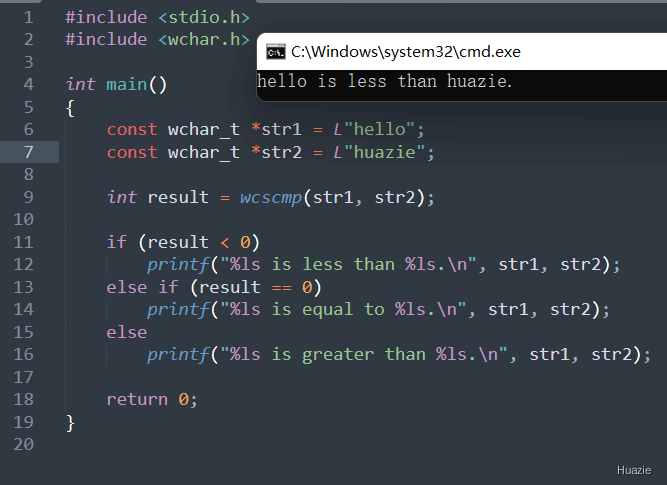
| 函数声明 | 函数功能 |
|---|---|
int wcscoll(const wchar_t *str1, const wchar_t *str2); |
用于比较两个宽字符串的大小 |
参数:
1 |
|
在上述的示例代码中,
setlocale() 函数设置本地化环境为当前系统默认设置;str1 和 str2,分别初始化为 “hello” 和 “huazie”;wcscoll() 函数比较两个字符串的大小,并将返回结果保存在变量 result 中。result 的值,输出相应的比较结果。注意: 在使用 wcscoll() 函数比较宽字符串大小时,需要确保本地化环境正确设置,以便该函数能够正常工作。如果没有设置本地化环境或者设置错误,可能会导致比较结果不准确。
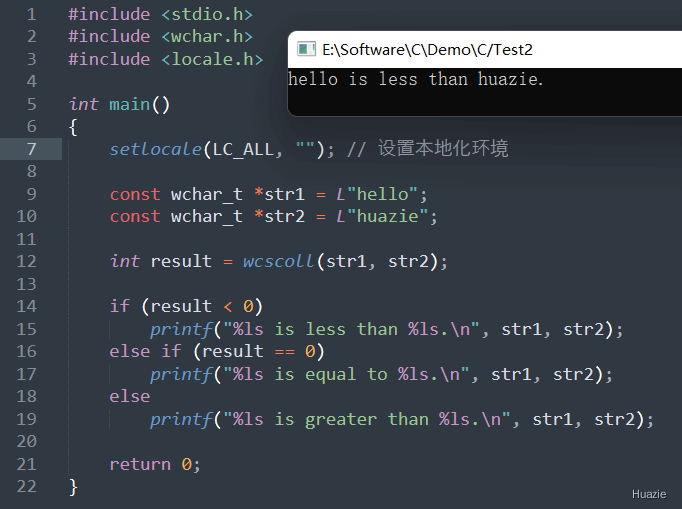
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcscpy(wchar_t *dest, const wchar_t *src); |
用于将一个宽字符串复制到另一个字符串中 |
参数:
1 |
|
在上述的示例代码中,
20 的 wchar_t 数组 dest;src,指向字符串 “Hello, huazie!”;wcscpy() 函数将 src 字符串中的所有字符复制到 dest 字符串中,形成新的宽字符字符串 dest;wprintf() 函数将新的字符串输出到控制台。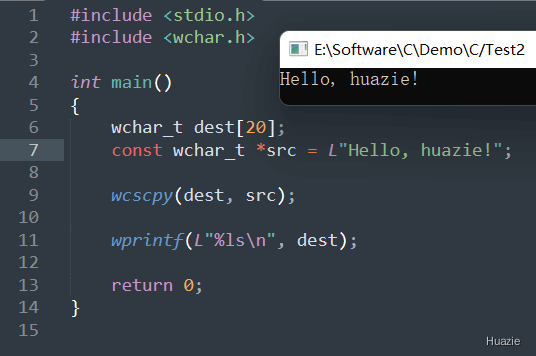
| 函数声明 | 函数功能 |
|---|---|
size_t wcsftime(wchar_t *str, size_t maxsize, const wchar_t *format, const struct tm *timeptr); |
用于将日期和时间格式化为宽字符字符串 |
参数:
1 |
|
在上面的示例代码中,
current_time 来存储当前时间,以及一个指向 struct tm 类型的指针 time_info;time() 函数获取当前时间,并使用 localtime() 函数将时间转换为本地时间,存储在 time_info 指针变量中;wcsftime() 函数将日期和时间格式化为宽字符字符串,并存储到缓冲区 buffer 中;wprintf() 函数输出格式化后的字符串。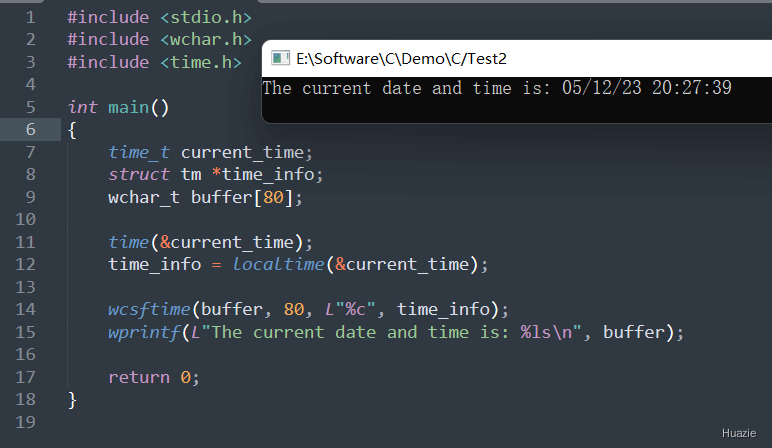
| 函数声明 | 函数功能 |
|---|---|
size_t wcslen(const wchar_t *str); |
用于计算宽字符串的长度 |
参数:
1 |
|
在上面的示例代码中,
str,指向字符串 "Hello, huazie!";wcslen() 函数计算 str 字符串的长度,并将结果保存在变量 len 中;wprintf() 函数输出字符串的长度。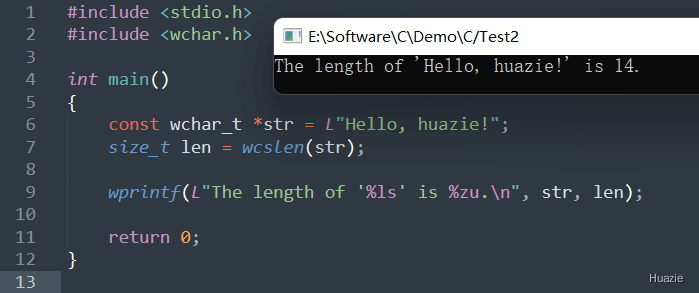
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcsncat(wchar_t *dest, const wchar_t *src, size_t n); |
用于将一个宽字符串的一部分追加到另一个宽字符串末尾 |
参数:
1 |
|
在上述的示例代码中,
20 的 wchar_t 数组 dest,并初始化为 "Hello, ";src,指向字符串 "huazie!"。wcsncat() 函数将 src 字符串中的前 3 个字符追加到 dest 字符串的末尾,形成新的宽字符字符串 dest;wprintf() 函数将新的字符串输出到控制台。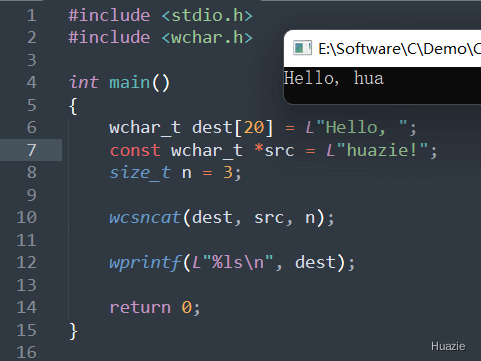
| 函数声明 | 函数功能 |
|---|---|
int wcsncmp(const wchar_t *str1, const wchar_t *str2, size_t n); |
用于比较两个宽字符串的前若干个字符是否相同 |
参数:
返回值:
将字符串 str1 和字符串 str2 中的前 n 个字符进行比较
0;str1 在前 n 个字符中的第一个不同于字符串 str2 对应字符的字符大于字符串 str2 对应字符的字符,返回值为正数;str1 在前 n 个字符中的第一个不同于字符串 str2 对应字符的字符小于字符串 str2 对应字符的字符,返回值为负数。1 |
|
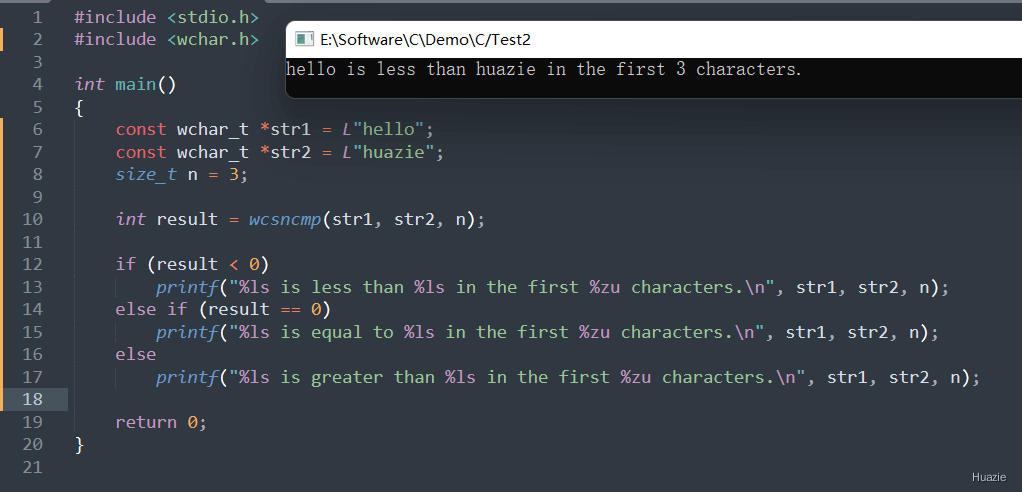
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcsncpy(wchar_t *dest, const wchar_t *src, size_t n); |
用于将一个宽字符串的一部分复制到另一个宽字符串中 |
参数:
1 |
|
在上面的示例代码中,
20 的 wchar_t 数组 dest,以及一个指向常量宽字符串的指针 src,指向字符串 "Hello, huazie!";wcsncpy() 函数将 src 字符串中的前 5 个字符复制到 dest 字符串中,形成新的宽字符字符串 dest;\0 以确保字符串结束,并使用 wprintf() 函数将新的字符串输出到控制台。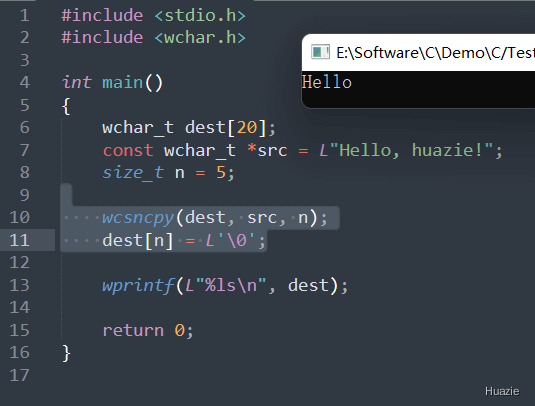
| 函数声明 | 函数功能 |
|---|---|
size_t wcsrtombs(char *dest, const wchar_t **src, size_t n, mbstate_t *ps); |
用于将宽字符串转换为多字节字符串 |
参数:
1 |
|
在上面的示例代码中,
setlocale() 函数设置程序的本地化环境,以便可以正确地进行宽字符和多字节字符之间的转换;src,指向字符串 "Hello, huazie!";dest,并初始化为 0;wcsrtombs() 函数将宽字符串 src 转换为多字节字符串,并存储到缓冲区 dest 中;printf() 函数输出多字节字符串,并释放目标缓存区的内存。注意: 在使用 wcsrtombs() 函数进行宽字符和多字节字符转换时,需要确保程序的本地化环境已经正确设置,否则可能会导致转换失败或者输出结果不正确。此外,在分配缓冲区 dest 的大小时,可以考虑将源字符串的长度加 1,以容纳字符串的结尾空字符(\0)。最后在使用完毕后要记得释放缓冲区的内存。
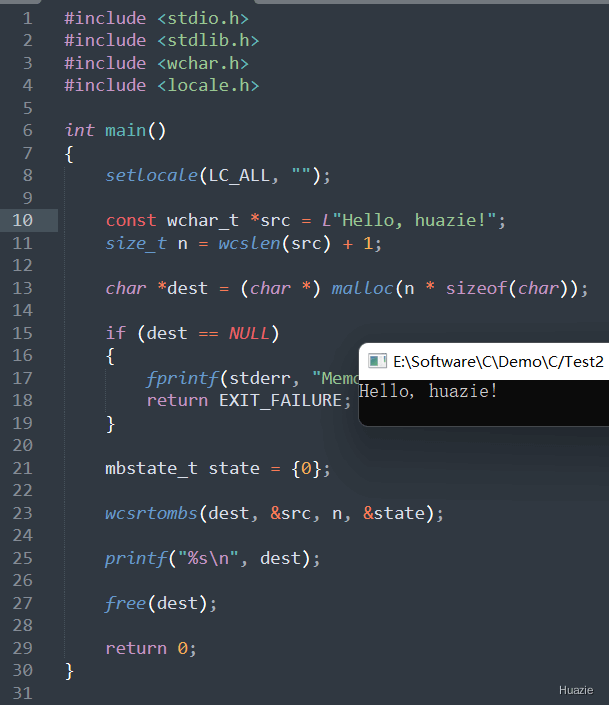
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcsstr(const wchar_t *haystack, const wchar_t *needle); |
用于在一个宽字符串中查找另一个宽字符串 |
参数:
返回值:
haystack 字符串中查找到第一个匹配 needle 子串的位置,则返回指向匹配位置的指针;NULL)。1 |
|
在上述的示例代码中,
haystack,指向字符串 "Hello, huazie!"。needle,指向字符串 "huazie";wcsstr() 函数在 haystack 字符串中查找子串 needle,并将结果指针保存在变量 result 中。result 的值,输出相应的查找结果。注意: 在使用 wcsstr() 函数查找子串时,该函数会自动遍历整个字符串,直到找到匹配的子串或者结束字符串。如果要查找的子串在字符串中多次出现,该函数将返回第一次出现的位置,并不会考虑后续的匹配。
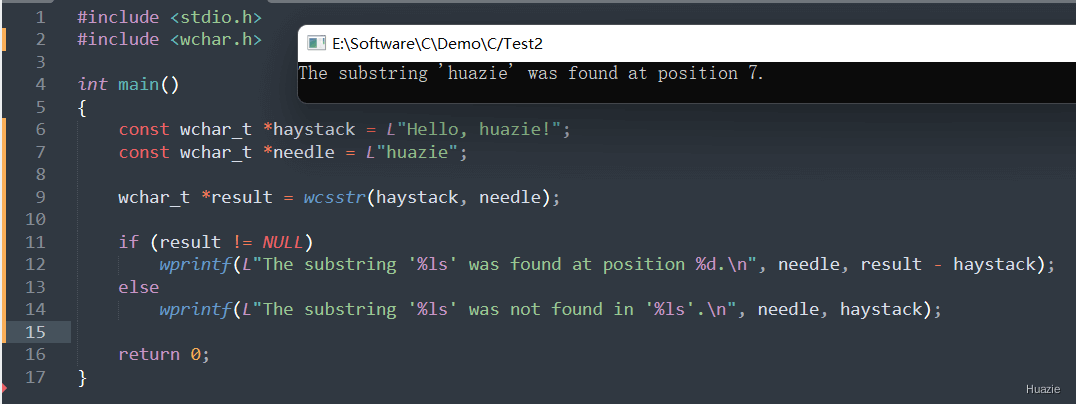
| 函数声明 | 函数功能 |
|---|---|
size_t wcsspn(const wchar_t *str, const wchar_t *accept); |
用于查找宽字符串中连续包含某些字符集合中的字符的最长前缀 |
参数:
1 |
|
在上述的示例代码中,
str,指向字符串 "123456789a0";accept,指向字符串 "0123456789",表示数字字符的集合;wcsspn() 函数查找 str 字符串中连续包含数字字符集合中的字符的最长前缀,并将返回结果保存在变量 length 中。length 的值,调用 wprintf() 函数 输出 最长前缀的长度。注意: 在使用 wcsspn() 函数查找宽字符串中的字符集合时,该函数会自动遍历整个字符串,直到找到第一个不在字符集合中的字符或者结束字符串。如果要查找的字符集合为空串,则返回 0。
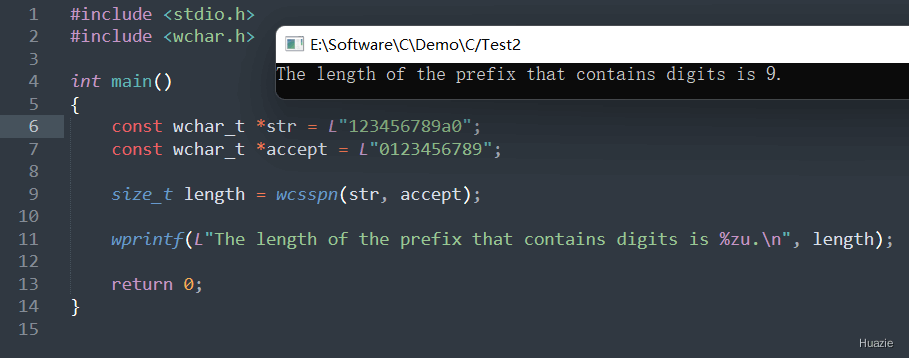
| 函数声明 | 函数功能 |
|---|---|
double wcstod(const wchar_t *nptr, wchar_t **endptr); |
用于将宽字符串转换为双精度浮点数 |
参数:
返回值:
nptr 字符串中解析出一个双精度浮点数,则返回该数值;nptr 字符串不包含有效的浮点数,则返回 0;endptr 指针中。1 |
|
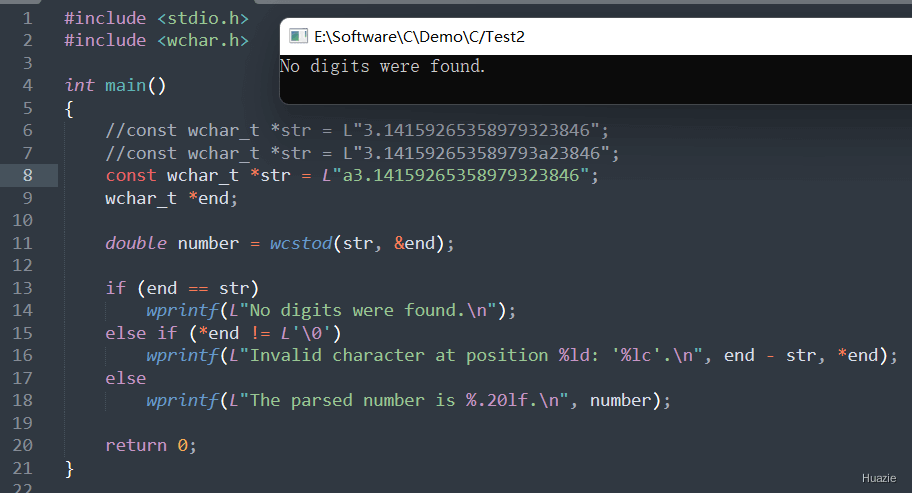
在上面的示例代码中,
str,指向字符串 "3.14159265358979323846";wcstod() 函数将字符串转换为双精度浮点数,并将结果保存在变量 number 中。number 和 endptr 指针所指向的值,输出相应的转换结果。注意: 在使用 wcstod() 函数转换宽字符串为双精度浮点数时,要确保字符串中只包含有效的浮点数表示,否则可能会导致转换错误或者未定义行为。
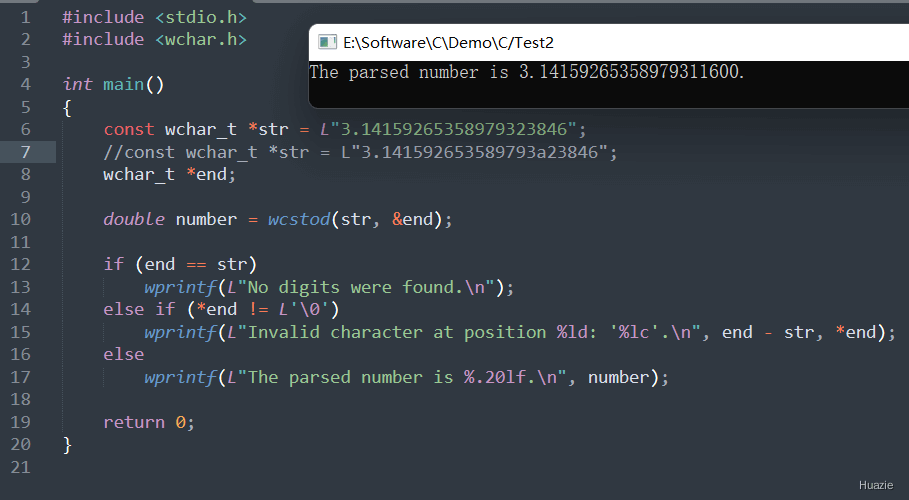
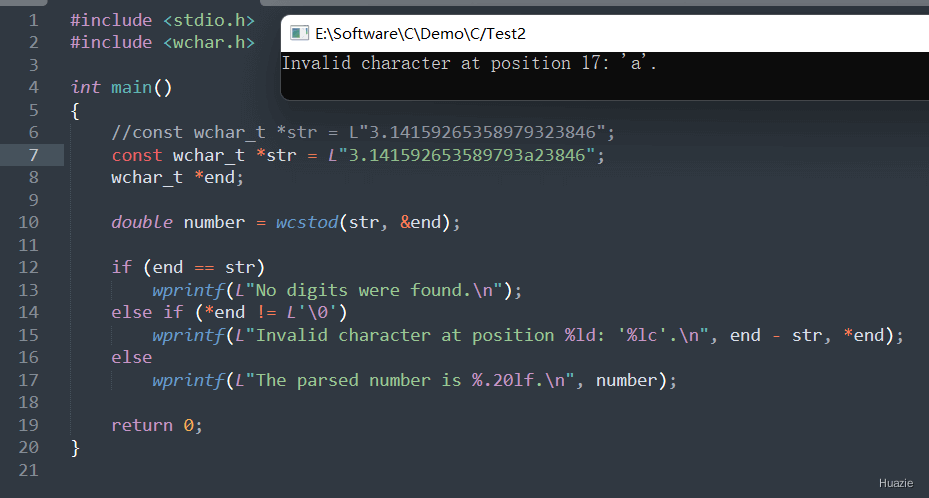
![]()
| 函数声明 | 函数功能 |
|---|---|
void va_start(va_list ap, last_arg); |
用于初始化一个 va_list 类型的变量,使其指向可变参数列表中的第一个参数 |
type va_arg(va_list ap, type); |
用于从可变参数列表中获取下一个参数,并将其转换为指定的类型 |
void va_copy(va_list dest, va_list src); |
用于将一个 va_list 类型的变量复制到另一个变量中 |
void va_end(va_list ap); |
用于清理一个 va_list 类型的变量 |
int vfprintf(FILE *stream, const char *format, va_list arg); |
用于将格式化输出写入到指定的文件流中 |
int vfscanf(FILE *stream, const char *format, va_list arg); |
用于将指定文件流中的格式化输入读取到指定变量中 |
int vprintf(const char *format, va_list ap); |
它使用格式化字符串 format 中的指令来指定输出的格式,并将后续的可变参数按照指令指定的格式输出到标准输出流 stdout |
int vscanf(const char *format, va_list arg); |
它使用格式化字符串 format 中的指令来指定输入的格式,并从标准输入流 stdin 中读取数据,并将数据按照指令指定的格式存储到相应的变量中 |
int vsprintf(char *str, const char *format, va_list ap); |
它使用格式化字符串 format 中的指令来指定输出的格式,并将后续的可变参数按照指令指定的格式输出到字符数组 str 中。 |
int vsscanf(const char *str, const char *format, va_list ap); |
它使用格式化字符串 format 中的指令来指定输入的格式,并从字符数组 str 中读取数据,并将数据按照指令指定的格式存储到相应的变量中 |
| 函数声明 | 函数功能 |
|---|---|
void va_start(va_list ap, last_arg); |
用于初始化一个 va_list 类型的变量,使其指向可变参数列表中的第一个参数 |
参数:
1 |
|
在上面的示例代码中,
print_args() 函数,并传入了 4 个入参,第一个为 可变参数的个数,后面三个为具体的整数型可变参数。print_args() 函数内部,我们首先定义了两个 va_list 类型的变量 args1 和 args2,并使用 va_start() 函数初始化 args1 变量。va_copy() 函数将 args1 复制到 args2 中,并使用 for 循环和 两个 va_arg() 函数来分别访问这两个可变参数列表,并依次输出每个参数的值。va_end() 函数来清理这两个可变参数列表。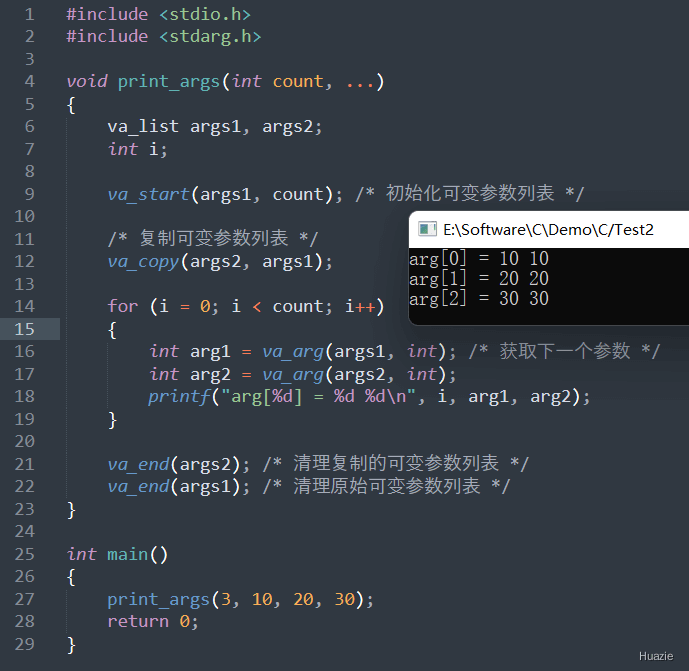
| 函数声明 | 函数功能 |
|---|---|
type va_arg(va_list ap, type); |
用于从可变参数列表中获取下一个参数,并将其转换为指定的类型 |
参数:
可参考 1.2 中所示
| 函数声明 | 函数功能 |
|---|---|
void va_copy(va_list dest, va_list src); |
用于将一个 va_list 类型的变量复制到另一个变量中 |
参数:
可参考 1.2 中所示
| 函数声明 | 函数功能 |
|---|---|
void va_end(va_list ap); |
用于清理一个 va_list 类型的变量 |
参数:
可参考 1.2 中所示
| 函数声明 | 函数功能 |
|---|---|
int vfprintf(FILE *stream, const char *format, va_list arg); |
用于将格式化输出写入到指定的文件流中 |
参数:
va_list 类型的变量,包含了可变参数列表1 |
|
在上述的示例代码中,
inumber、fnumber 和 string;tmpfile() 函数创建一个临时文件,并将返回的文件指针赋值给全局变量 fp。如果创建文件失败,则打印错误信息并退出程序;vfpf() 函数来向临时文件中写入数据。它里面使用 vfprintf() 函数将格式化输出写入到一个文件流中;rewind() 函数将文件指针重新定位到文件开头;fscanf() 函数从文件中读取数据,并使用 printf() 函数中输出从文件中读取的数据【其中浮点数部分保留两位小数】fclose() 函数关闭文件指针,并结束程序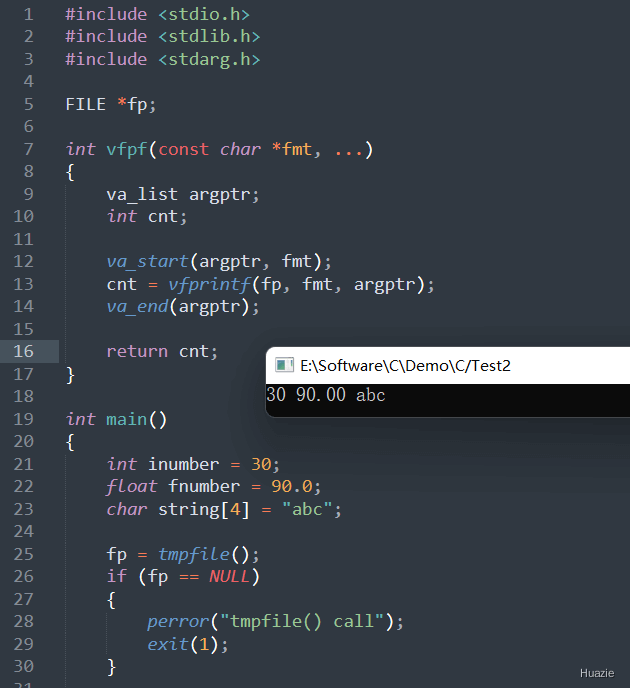
| 函数声明 | 函数功能 |
|---|---|
int vfscanf(FILE *stream, const char *format, va_list arg); |
用于将指定文件流中的格式化输入读取到指定变量中 |
参数:
va_list 类型的变量,包含了可变参数列表返回值:
1 |
|
在上面的示例代码中,
inumber、fnumber 和 string;tmpfile() 函数创建一个临时文件,并将返回的文件指针赋值给全局变量 fp。如果创建文件失败,则打印错误信息并退出程序;fprintf() 函数将三个数据(一个整型数字、一个浮点数和一个字符串)写入该文件中;rewind() 函数将文件指针重新定位到文件开头;vfsf() 函数,里面使用 vfscanf() 函数从文件中读取数据;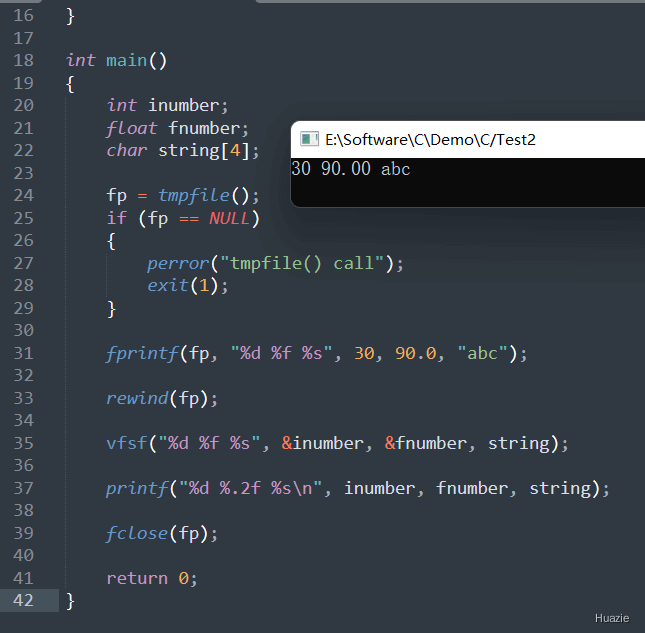
| 函数声明 | 函数功能 |
|---|---|
int vprintf(const char *format, va_list ap); |
它使用格式化字符串 format 中的指令来指定输出的格式,并将后续的可变参数按照指令指定的格式输出到标准输出流 stdout |
参数:
va_list 类型的变量,包含了可变参数列表1 |
|
在上面的示例代码中,
a 、浮点型 b 和 字符数组 s;myprint() 函数将这些变量的值输出到标准输出流 stdout 中;myprint() 函数中, va_start() 宏初始化一个 va_list 变量 args;vprintf() 函数将格式化字符串和参数列表传递给该函数进行输出;va_end() 宏清理 args 变量。
| 函数声明 | 函数功能 |
|---|---|
int vscanf(const char *format, va_list arg); |
它使用格式化字符串 format 中的指令来指定输入的格式,并从标准输入流 stdin 中读取数据,并将数据按照指令指定的格式存储到相应的变量中 |
参数:
va_list 类型的变量,包含了可变参数列表1 |
|
在上面的示例代码中,
a 、浮点型 b 和 字符数组 s;myscan() 函数从标准输入流 stdin 中读取数据,并将数据存储到这些变量中myscan() 函数中, va_start() 宏初始化一个 va_list 变量 args;vscanf() 函数将格式化字符串和参数列表传递给该函数进行输入;va_end() 宏清理 args 变量。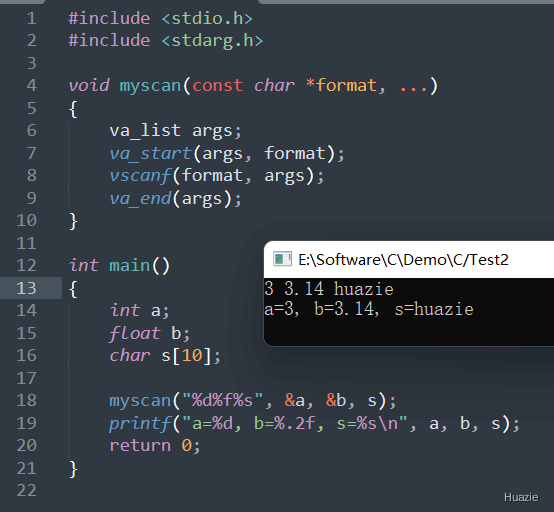
| 函数声明 | 函数功能 |
|---|---|
int vsprintf(char *str, const char *format, va_list ap); |
它使用格式化字符串 format 中的指令来指定输出的格式,并将后续的可变参数按照指令指定的格式输出到字符数组 str 中。 |
参数:
va_list 类型的变量,包含了可变参数列表1 |
|
在上面的示例代码中,
a 、浮点型 b 和 字符数组 s;myprint() 函数将格式化字符串和这些变量的值输出到字符数组 buffer 中,并打印输出字符数组 buffer ;myprint() 函数中, va_start() 宏初始化一个 va_list 变量 args;vsprintf() 函数将格式化字符串和参数列表传递给该函数进行输出,并将输出结果存储到 buffer 数组中;va_end() 宏清理 args 变量。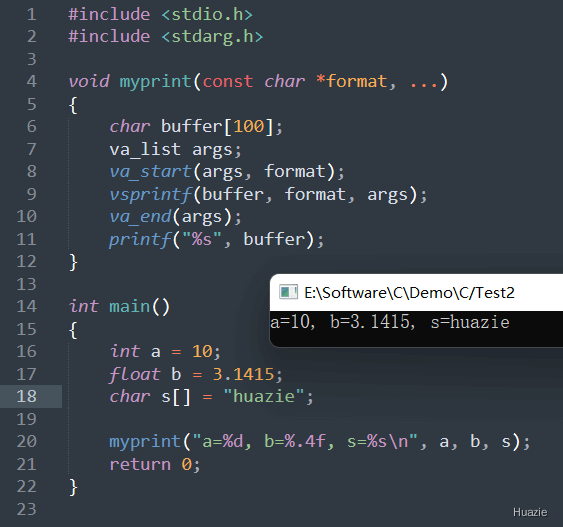
| 函数声明 | 函数功能 |
|---|---|
int vsscanf(const char *str, const char *format, va_list ap); |
它使用格式化字符串 format 中的指令来指定输入的格式,并从字符数组 str 中读取数据,并将数据按照指令指定的格式存储到相应的变量中 |
参数:
va_list 类型的变量,包含了可变参数列表1 |
|
在上面的示例代码中,
a 、浮点型 b 、 字符数组 s 和 字符数组 buffer;myscan() 函数从字符数组 buffer 中读取数据,并将数据存储到另外 3 个变量中;myscan() 函数中, va_start() 宏初始化一个 va_list 变量 args;vsscanf() 函数将字符数组 buffer 和格式化字符串以及参数列表传递给该函数进行输入,并将数据存储到相应的变量中;va_end() 宏清理 args 变量。buffer 中读取并输入的三个变量的数据,并结束程序。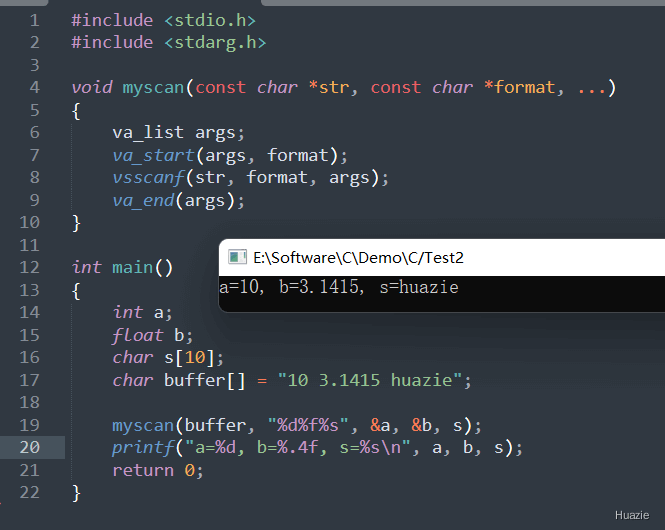
![]()
| 函数声明 | 函数功能 |
|---|---|
char *ultoa(unsigned long value, char *str, int base); |
用于将无符号长整型数转换成指定基数下的字符串表示 |
int ungetc(int c, FILE *stream); |
用于将字符推回输入流中 |
int ungetch(int c); |
用于将字符推回输入流中 |
int unix2dos(const char *src_file, const char *dst_file); |
用于将文本文件的行末标志符从 Unix 风格的 \n 转换为 Windows/DOS 风格的 \r\n |
int dos2unix(const char *src_file, const char *dst_file); |
用于将将文本文件的行末标志符从 Windows/DOS 风格的 \r\n 转换为 Unix 风格的 \n |
int unlink(const char *pathname); |
用于删除指定文件 |
int unlock(int handle, long offset, long length); |
它不是标准 C 库中的函数,而是 Linux/Unix 系统下用于文件锁定和解锁的函数 |
BOOL UnlockFile(HANDLE hFile, DWORD dwFileOffsetLow, DWORD dwFileOffsetHigh, DWORD nNumberOfBytesToUnlockLow, DWORD nNumberOfBytesToUnlockHigh); |
用于对文件进行解锁操作 |
| 函数声明 | 函数功能 |
|---|---|
char *ultoa(unsigned long value, char *str, int base); |
用于将无符号长整型数转换成指定基数下的字符串表示 |
参数:
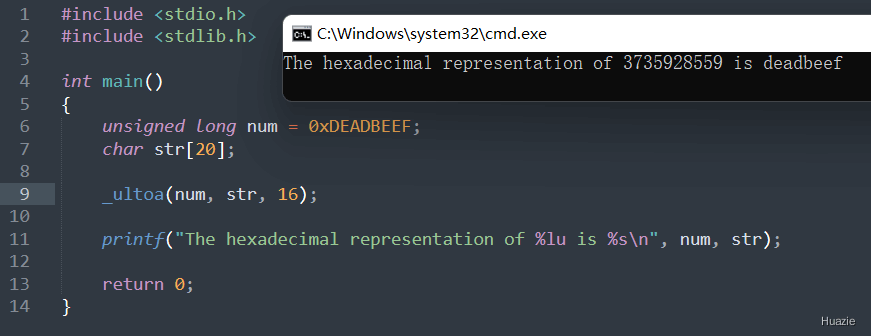
函数 ultoa() 将参数 value 转换为以 base 进制表示的形式,并将结果存储在缓冲区 str 中。如果转换成功,则返回指向 str 的指针。
注意: 函数 ultoa() 不会检查缓冲区是否足够大,因此调用者需要确保缓冲区足够大以避免发生缓冲区溢出。
1 |
|
| 函数声明 | 函数功能 |
|---|---|
int ungetc(int c, FILE *stream); |
用于将字符推回输入流中 |
参数:
1 |
|
在上面的示例代码中,
test.txt 的文本文件;fgetc() 函数从中读取一个字符;ungetc() 函数将该字符推回输入流中;fgetc() 函数从输入流中读取字符;printf() 函数将两次读取的字符打印到标准输出流中。注意: 在使用 ungetc() 函数推回字符之前,必须先读取一个字符并检查其是否成功读取。否则,ungetc() 函数将无法确定将字符推回哪个位置。
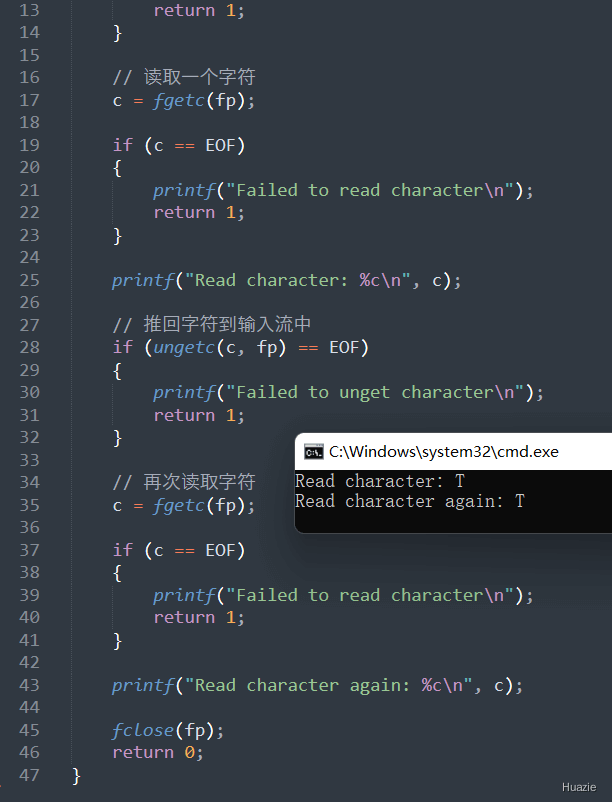
| 函数声明 | 函数功能 |
|---|---|
int ungetch(int c); |
用于将字符推回输入流中 |
参数:
1 |
|
在上述的示例代码中,
"Input an integer followed by a char:"getche() 函数从输入流中逐个读取字符,并检查它是否是数字字符。如果是数字字符,则将其转换为整数并存储在变量 i 中。ungetch() 函数将该字符推回输入流中,以保留它供后续使用。getch() 函数从输入流中读取一个字符,并打印出读取到的下一个字符和此时 i 的值。注意: getch() 和 ungetch() 函数通常只在 Windows 平台上可用,因此这段代码可能不可移植到其他操作系统或编译器中。

| 函数声明 | 函数功能 |
|---|---|
int unix2dos(const char *src_file, const char *dst_file); |
用于将文本文件的行末标志符从 Unix 风格的 \n 转换为 Windows/DOS 风格的 \r\n |
int dos2unix(const char *src_file, const char *dst_file); |
用于将将文本文件的行末标志符从 Windows/DOS 风格的 \r\n 转换为 Unix 风格的 \n |
参数:
返回值:
0;1 |
|
| 函数声明 | 函数功能 |
|---|---|
int unlink(const char *pathname); |
用于删除指定文件 |
参数:
1 |
|
在上面的示例代码中,我们使用 unlink() 函数删除了当前目录下名为 huazie.txt 的文件。如果 unlink() 函数返回值不为 0,则说明删除操作失败,可能是由于权限不足、文件不存在或其他原因导致的。如果删除操作成功,则会输出一条简短的提示信息 "File deletion successful"。
注意: 由于删除操作无法撤销,并且被删除的文件内容将无法恢复,因此在使用 unlink() 函数删除文件时需要小心谨慎,建议在执行此类敏感操作之前进行备份或确认。
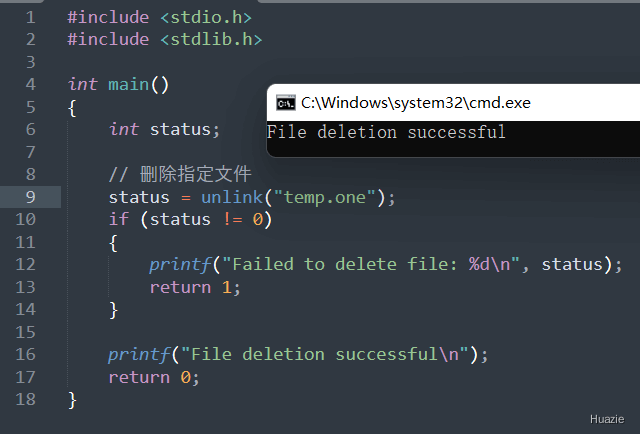
| 函数声明 | 函数功能 |
|---|---|
int unlock(int handle, long offset, long length); |
它不是标准 C 库中的函数,而是 Linux/Unix 系统下用于文件锁定和解锁的函数 |
参数:
offset 参数小于零,则将从文件末尾开始向前计算偏移量。1 |
|
| 函数声明 | 函数功能 |
|---|---|
BOOL UnlockFile(HANDLE hFile, DWORD dwFileOffsetLow, DWORD dwFileOffsetHigh, DWORD nNumberOfBytesToUnlockLow, DWORD nNumberOfBytesToUnlockHigh); |
用于对文件进行解锁操作 |
参数:
4GB,因此需要使用两个参数表示完整的偏移量1 |
|
在上面的示例代码中,
Windows API 中的 CreateFile() 函数打开名为 test.txt 的文件,并获取其文件句柄;WriteFile() 函数将字符串写入文件;LockFile() 函数对文件进行锁定操作,并使用 UnlockFile() 函数进行解锁操作;注意:在使用 UnlockFile() 函数时,需要确保已经使用 CreateFile() 或其他文件打开函数打开了文件,并获得了有效的文件句柄。

![]()
| 函数声明 | 函数功能 |
|---|---|
double tan(double x) |
计算 以弧度 x 为单位的角度的正切值(double) |
float tanf(float x) |
计算 以弧度 x 为单位的角度的正切值(float) |
long double tanl(long double x) |
计算 以弧度 x 为单位的角度的正切值(long double) |
double tanh(double x); |
计算 x 的双曲正切值(double) |
float tanhf(float x); |
计算 x 的双曲正切值(float) |
long double tanhl(long double x); |
计算 x 的双曲正切值(long double) |
off_t tell(int fd); |
用于返回文件指针当前位置相对于文件开头的偏移量 |
long int telldir(DIR *dirp); |
获取目录流的当前位置 |
int textheight(char *string); |
用于获取当前文本模式下字符的高度 |
int textwidth(char *string); |
用于获取当前文本模式下字符的宽度 |
time_t time(time_t *timer); |
可以用于获取从 1970 年 1 月 1 日 00:00:00 UTC 到当前时间的秒数 |
FILE *tmpfile(void); |
可以用于在临时目录中创建一个唯一的临时文件,并返回文件指针 |
char *tmpnam(char *s); |
用于创建一个唯一的临时文件名 |
int toascii(int c); |
将一个字符转换为其对应的 ASCII 码值 |
int tolower(int c); |
可以用于将一个 ASCII 字符转换为小写字母 |
int toupper(int c); |
可以用于将一个 ASCII 字符转换为大写字母 |
double trunc(double x); |
截取 x 的小数部分,并返回整数部分(double) |
float truncf(float x); |
截取 x 的小数部分,并返回整数部分(float) |
long double truncl(long double x); |
截取 x 的小数部分,并返回整数部分(long double) |
void tzset(void); |
可以用于设置时区信息 |
double tgamma(double x); |
用于计算 Gamma 函数(double) |
float tgammaf(float x); |
用于计算 Gamma 函数(float) |
long double tgammal(long double x); |
用于计算 Gamma 函数(long double) |
| 函数声明 | 函数功能 |
|---|---|
double tan(double x) |
计算 以弧度 x 为单位的角度的正切值(double) |
float tanf(float x) |
计算 以弧度 x 为单位的角度的正切值(float) |
long double tanl(long double x) |
计算 以弧度 x 为单位的角度的正切值(long double) |
1 |
|
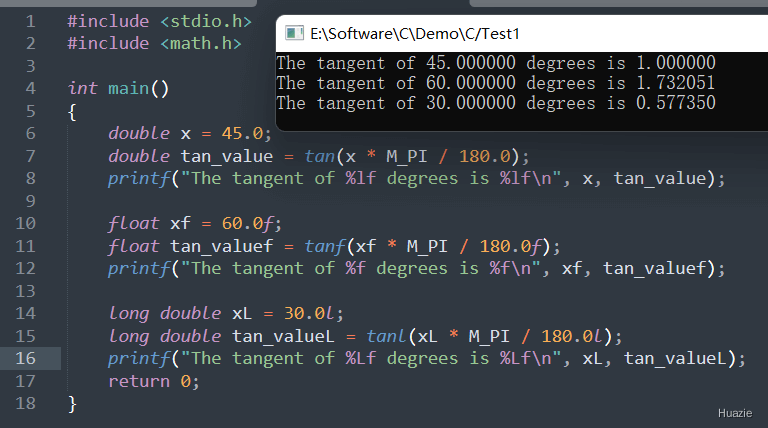
| 函数声明 | 函数功能 |
|---|---|
double tanh(double x); |
计算 x 的双曲正切值(double) |
float tanhf(float x); |
计算 x 的双曲正切值(float) |
long double tanhl(long double x); |
计算 x 的双曲正切值(long double) |
1 |
|
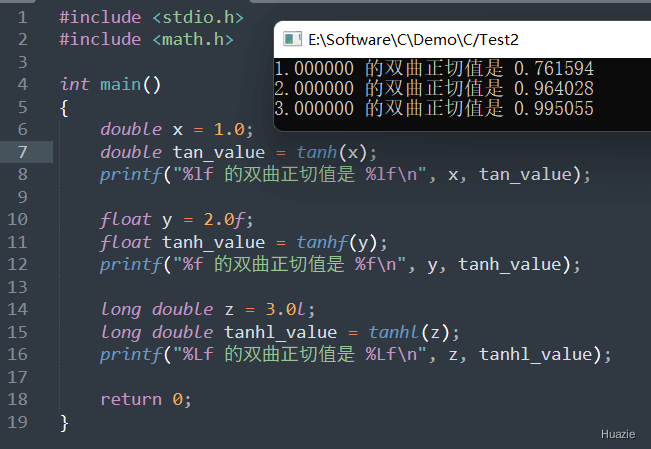
| 函数声明 | 函数功能 |
|---|---|
off_t tell(int fd); |
用于返回文件指针当前位置相对于文件开头的偏移量 |
参数:
1 |
|
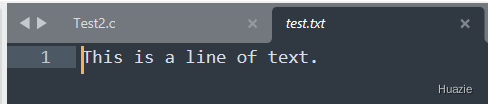
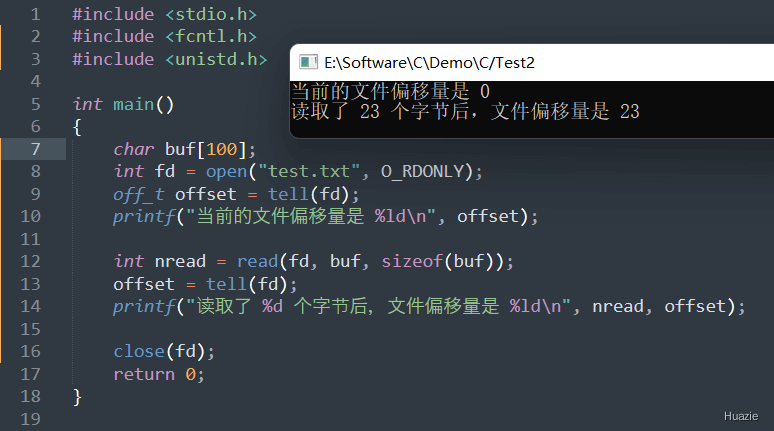
在上面这个示例中,
tell() 函数获取了当前的文件偏移量。read() 函数读取了一些数据,并再次使用 tell() 函数来获取新的文件偏移量。close() 函数关闭文件。注意:tell() 函数和 lseek 函数的功能类似,但有一个重要的区别:tell() 函数只用于查询当前位置,而不能修改文件指针的位置。如果要修改文件指针的位置,请使用 lseek() 函数。
下面我们来看看,使用 lseek() 函数来演示上面的 tell() 函数的示例 :
1 |
|
| 函数声明 | 函数功能 |
|---|---|
long int telldir(DIR *dirp); |
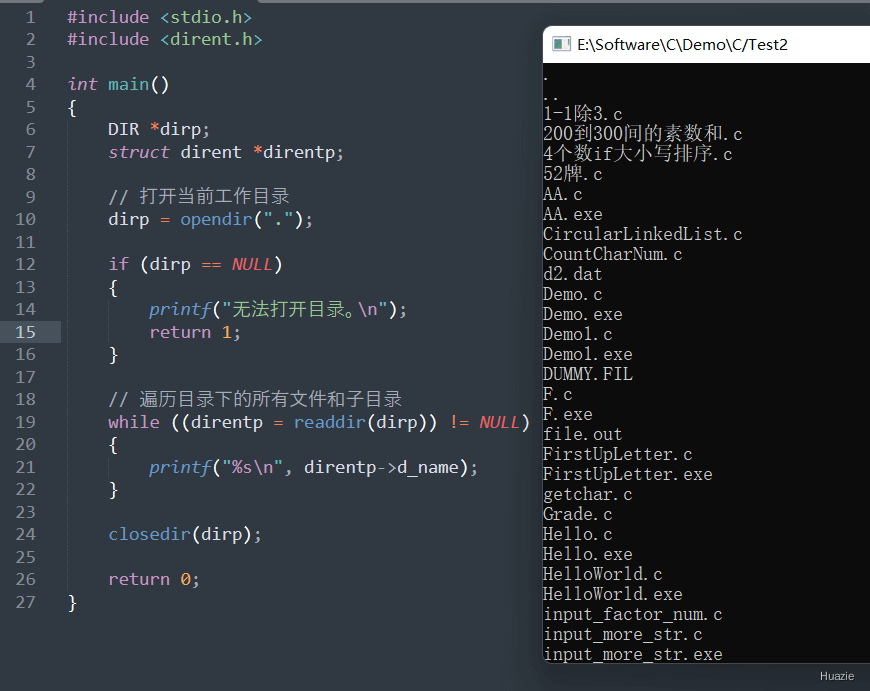
获取目录流的当前位置 |
参数:
DIR 类型结构体的指针1 |
|
| 函数声明 | 函数功能 |
|---|---|
int textheight(char *string); |
用于获取当前文本模式下字符的高度 |
int textwidth(char *string); |
用于获取当前文本模式下字符的宽度 |
参数:
1 |
|
| 函数声明 | 函数功能 |
|---|---|
time_t time(time_t *timer); |
可以用于获取从 1970 年 1 月 1 日 00:00:00 UTC 到当前时间的秒数 |
参数:
time_t 类型对象的指针,如果不想使用此参数,可以将它设置为 NULL1 |
|
在上面的示例中,
time() 函数来获取当前时间的秒数;ctime() 函数将其转换为可读的日期和时间格式;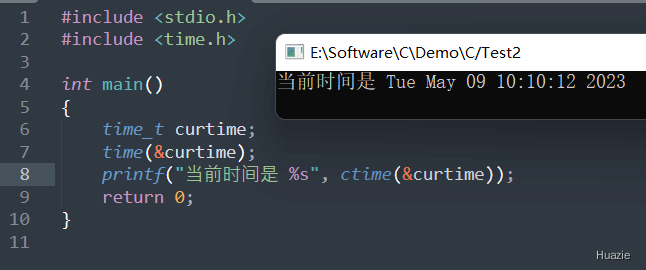
| 函数声明 | 函数功能 |
|---|---|
FILE *tmpfile(void); |
可以用于在临时目录中创建一个唯一的临时文件,并返回文件指针 |
1 |
|
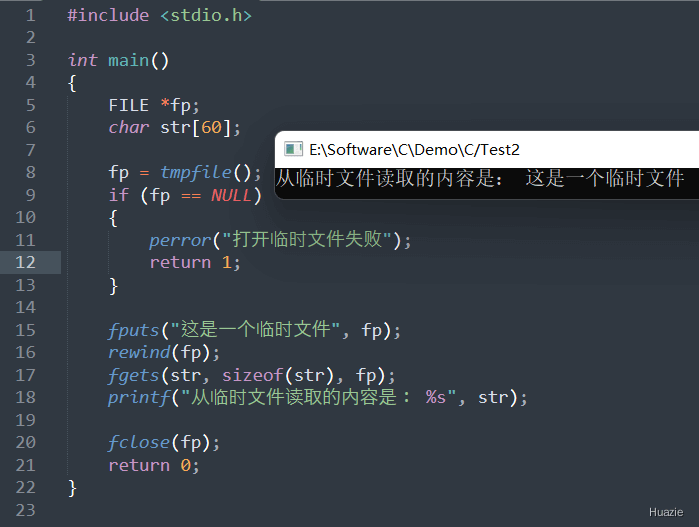
在上述的示例中,
tmpfile() 函数创建一个临时文件;fputs() 函数将字符串 "这是一个临时文件" 写入该文件;rewind() 函数将文件指针移动到文件开始处;fgets() 函数从临时文件中读取数据并将其存储到字符串数组 str 中;注意: 使用 tmpfile() 创建的临时文件只在程序运行期间存在,并在程序终止时自动删除。如果需要在程序运行期间保留临时文件,请使用 tmpnam() 或 mkstemp() 等函数来创建文件。
| 函数声明 | 函数功能 |
|---|---|
char *tmpnam(char *s); |
用于创建一个唯一的临时文件名 |
参数:
s 等于 NULL,则函数会返回指向静态内存区的指针,该内存区包含了唯一的临时文件名1 |
|
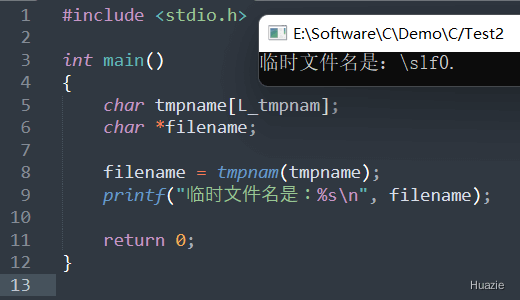
在上面的示例中,
tmpnam() 函数创建一个唯一的临时文件名;tmpname 中;注意: 使用 tmpnam() 创建的临时文件名只在程序运行期间存在,不具有真正唯一性,因此可能存在一定程度的风险。如果需要创建一个具有真正唯一性的临时文件,请考虑使用 mkstemp() 或类似的函数。
| 函数声明 | 函数功能 |
|---|---|
int toascii(int c); |
将一个字符转换为其对应的 ASCII 码值 |
参数:
1 |
|
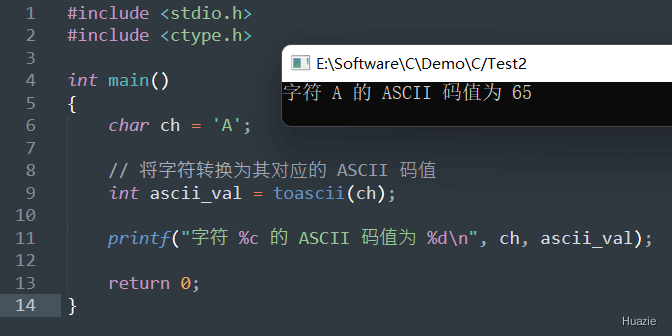
注意 : toascii() 函数已经过时,不建议在新代码中使用。在 C99 标准中,改用更安全的 isascii() 函数来检查字符是否为 7-bit ASCII 字符,并使用位掩码操作或其他算法来将非 ASCII 字符转换为相应的 7-bit ASCII 码值。
知识点: 7-bit ASCII,也称为美国信息交换标准代码 (American Standard Code for Information Interchange),是一种基于英语的字符编码系统,使用 7 个二进制位(即一个字节)表示每个字符。它涵盖了拉丁字母、数字、标点符号和一些特殊符号,共计 128 个字符。
| 函数声明 | 函数功能 |
|---|---|
int tolower(int c); |
可以用于将一个 ASCII 字符转换为小写字母 |
参数:
1 |
|
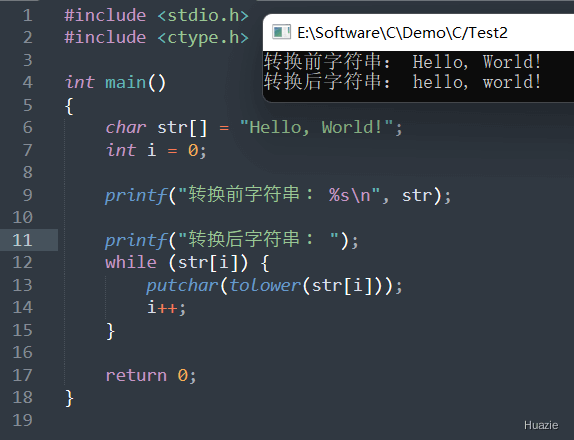
| 函数声明 | 函数功能 |
|---|---|
int toupper(int c); |
可以用于将一个 ASCII 字符转换为大写字母 |
参数:
1 |
|
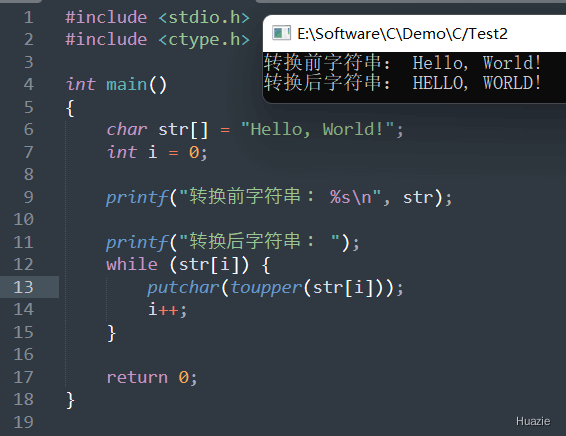
| 函数声明 | 函数功能 |
|---|---|
double trunc(double x); |
截取 x 的小数部分,并返回整数部分(double) |
float truncf(float x); |
截取 x 的小数部分,并返回整数部分(float) |
long double truncl(long double x); |
截取 x 的小数部分,并返回整数部分(long double) |
1 |
|
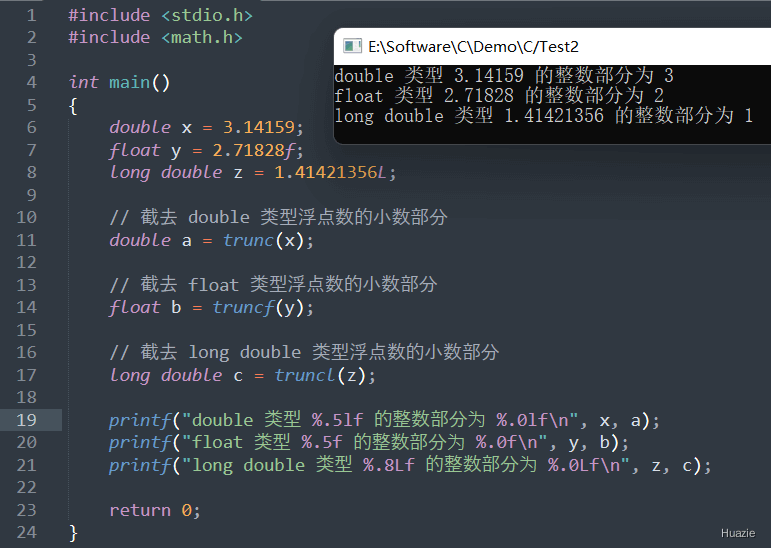
| 函数声明 | 函数功能 |
|---|---|
void tzset(void); |
可以用于设置时区信息 |
UNIX/Linux 下示例:
1 |
|
windows 下示例:
1 |
|
在上述示例代码中,
rawtime 和 timeinfo,分别用于存储当前时间和时间结构体。GetTimeZoneInformation() 函数获取当前系统时区信息,并将其存储在 tzinfo 变量中。WideCharToMultiByte() 函数将 tzinfo.StandardName 转换为 UTF-8 编码的字符串,并将其存储在 standard_name 变量中。putenv_s() 函数将 standard_name 设置为环境变量 TZ 的值,并使用 tzset 函数更新本地时区信息。localtime() 函数将 rawtime 转换为时间结构体 timeinfo。asctime() 函数将时间结构体 timeinfo 转换为字符串格式,并输出到标准输出流中。standard_name 分配的内存空间,并正常结束程序。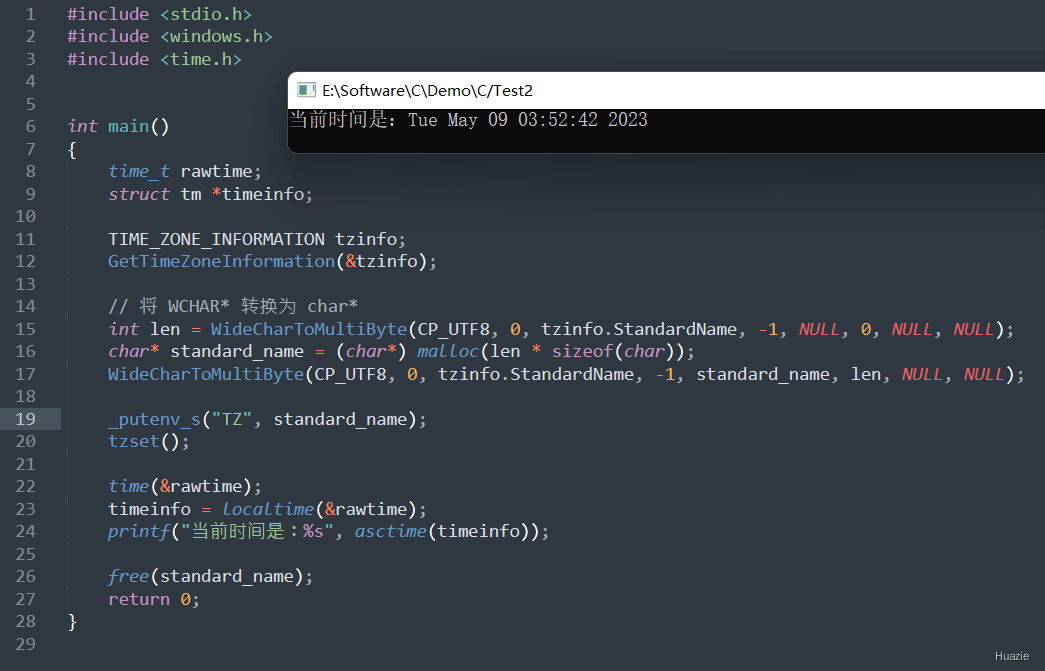
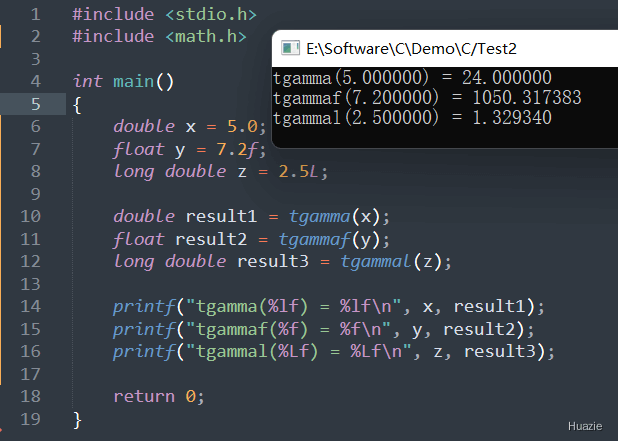
| 函数声明 | 函数功能 |
|---|---|
double tgamma(double x); |
用于计算 Gamma 函数(double) |
float tgammaf(float x); |
用于计算 Gamma 函数(float) |
long double tgammal(long double x); |
用于计算 Gamma 函数(long double) |
1 |
|
知识点: 伽玛函数(Gamma 函数),也叫欧拉第二积分,是阶乘函数在实数与复数上扩展的一类函数。
![]()
| 函数声明 | 函数功能 |
|---|---|
char * strdup(const char *s); |
用于将一个以 NULL 结尾的字符串复制到新分配的内存空间中 |
int stricmp(const char *s1, const char *s2); |
用于比较两个字符串的字母序是否相等,忽略大小写 |
char *strerror(int errnum); |
用于将指定的错误码转换为相应的错误信息 |
int strcmpi(const char *s1, const char *s2); |
用于比较两个字符串的字母序是否相等,忽略大小写 |
int strncmp(const char *s1, const char *s2, size_t n); |
用于比较两个字符串的前n个字符是否相等 |
int strncmpi(const char *s1, const char *s2, size_t n); |
用于比较两个字符串的前n个字符是否相等,忽略大小写 |
char *strncpy(char *dest, const char *src, size_t n); |
用于将一个字符串的一部分拷贝到另一个字符串中 |
int strnicmp(const char *s1, const char *s2, size_t n); |
用于比较两个字符串的前n个字符是否相等,忽略大小写 |
char *strnset(char *str, int c, size_t n); |
用于将一个字符串的前n个字符都设置为指定的字符 |
char *strpbrk(const char *str1, const char *str2); |
用于在一个字符串中查找任意给定字符集合中的字符的第一次出现位置 |
char *strrchr(const char *str, int character); |
在给定的字符串中查找指定字符的最后一个匹配项 |
char *strrev(char *str); |
将给定字符串中的所有字符顺序颠倒,并返回颠倒后的字符串 |
char *strset(char *str, int character); |
用于设置给定字符串中的所有字符为指定的值,并返回修改后的字符串 |
size_t strspn(const char *str1, const char *str2); |
计算字符串 str1 中包含在字符串 str2 中的前缀子字符串长度,并返回该长度值 |
char *strstr(const char *str1, const char *str2); |
在字符串 str1 中查找第一个出现的字符串 str2,如果找到了,则返回指向该位置的指针;否则,返回 NULL |
double strtod(const char *str, char **endptr); |
将字符串 str 转换为一个浮点数(double 类型),并返回该浮点数。如果发生了转换错误,则返回 0.0,并且可以通过 endptr 指针返回指向第一个无法转换的字符的指针。 |
char *strtok(char *str, const char *delim); |
用于将一个字符串分割成多个子字符串 |
long int strtol(const char *str, char **endptr, int base); |
将字符串 str 转换为一个长整型数(long int 类型) |
char *strupr(char *str); |
将字符串 str 中的所有小写字母转换为大写字母,并返回指向该字符串的指针 |
void swab(const void *src, void *dest, ssize_t nbytes); |
将源缓冲区中的每两个相邻字节进行互换,然后将结果存储到目标缓冲区中 |
int system(const char *command); |
执行一个 shell 或 cmd 命令,并等待命令的完成 |
| 函数声明 | 函数功能 |
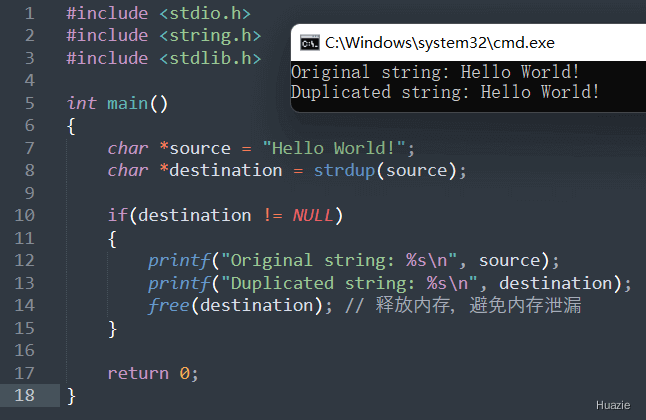
|---|---|
char * strdup(const char *s); |
用于将一个以 NULL 结尾的字符串复制到新分配的内存空间中 |
注意: strdup() 函数返回指向新分配的内存空间的指针,如果空间不足则返回 NULL。调用者负责释放返回的指针所指向的内存空间。 strdup() 函数与strcpy() 函数类似,但是它会动态地分配内存空间,而 strcpy() 需要调用者提供足够大的目标缓冲区。
1 |
|
| 函数声明 | 函数功能 |
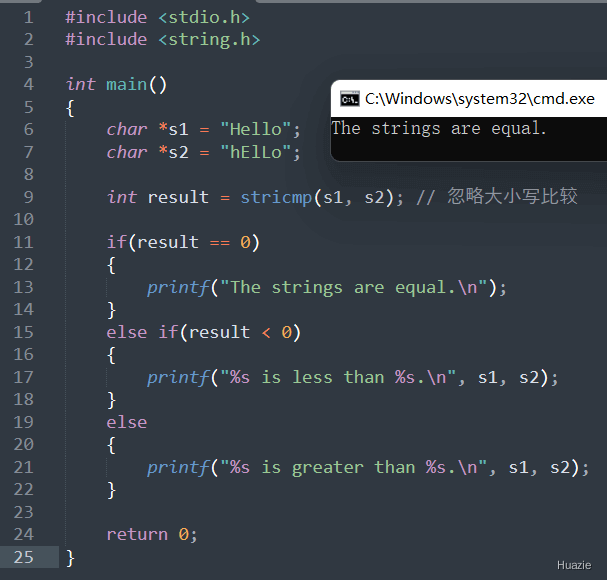
|---|---|
int stricmp(const char *s1, const char *s2); |
用于比较两个字符串的字母序是否相等,忽略大小写 |
返回值:
s1 和 s2 代表的字符串相等(忽略大小写),则返回 0;s1 比 s2 小,则返回负数;s1 比 s2 大,则返回正数。1 |
|
| 函数声明 | 函数功能 |
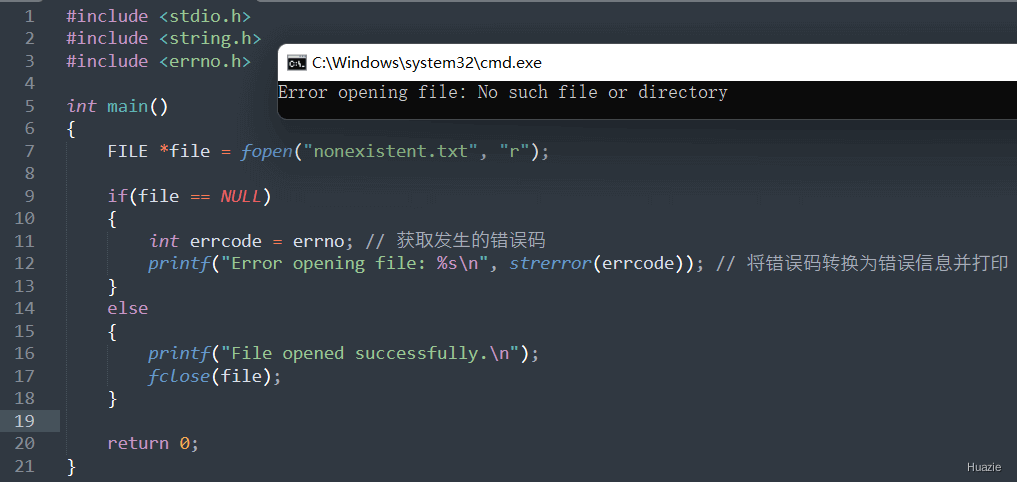
|---|---|
char *strerror(int errnum); |
用于将指定的错误码转换为相应的错误信息 |
参数:
返回值:
指向错误信息字符串的指针,该字符串描述了与错误码相关的错误
1 |
|
| 函数声明 | 函数功能 |
|---|---|
int strcmpi(const char *s1, const char *s2); |
用于比较两个字符串的字母序是否相等,忽略大小写 |
返回值:
s1 和 s2 代表的字符串相等(忽略大小写),则返回 0;s1 比 s2 小,则返回负数;s1 比 s2 大,则返回正数。1 |
|
看到这里,可能会疑惑 上面不是已经有了 忽略大小写的字符串比较了嘛?
那 strcmpi 和 stricmp 有什么区别呢?
虽然它们的实现功能相同,但是不同的编译器或操作系统可能会提供其中一个或两个函数。在具备这两个函数的系统中,strcmpi 常常作为 VC(Visual C++)和 Borland C++ 的扩展库函数,而 stricmp 则是 POSIX 标准中定义的函数,在许多 类UNIX系统 上可用。因此,如果需要编写可移植的代码,则应该使用 stricmp 函数,而不是 strcmpi 函数。
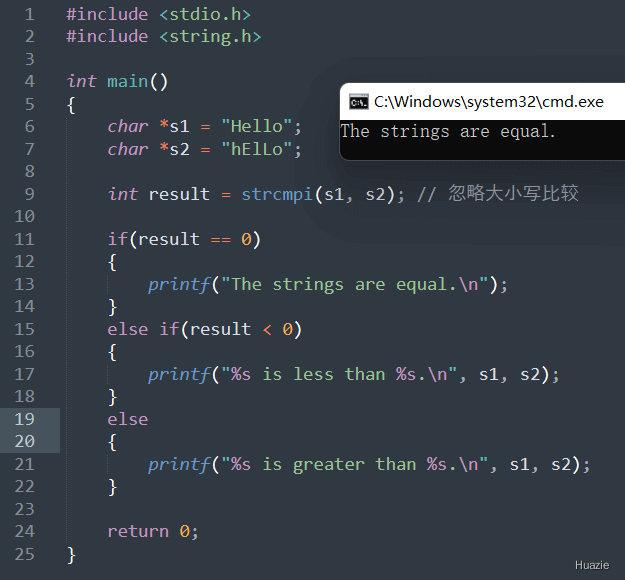
| 函数声明 | 函数功能 |
|---|---|
int strncmp(const char *s1, const char *s2, size_t n); |
用于比较两个字符串的前n个字符是否相等 |
参数:
返回值:
s1 和 s2 代表的字符串相等(忽略大小写),则返回 0;s1 比 s2 小,则返回负数;s1 比 s2 大,则返回正数。1 |
|
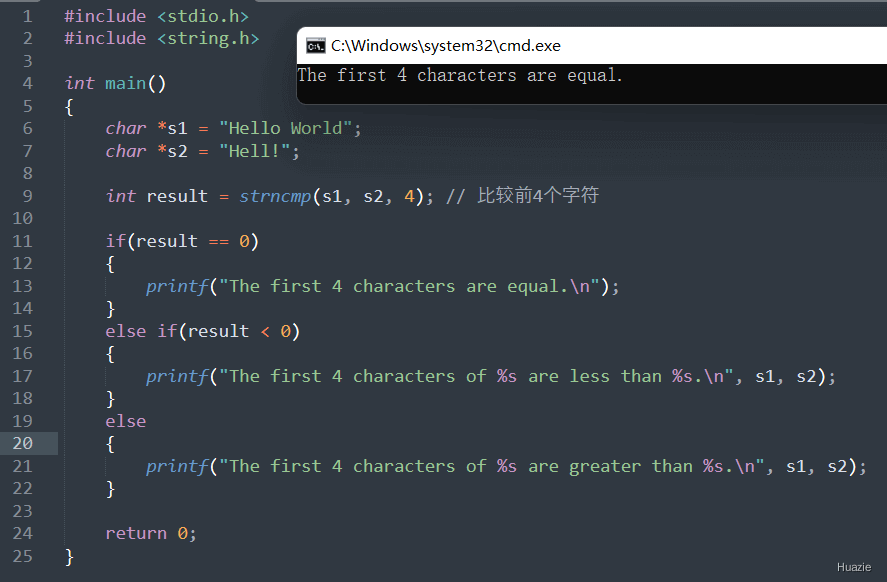
| 函数声明 | 函数功能 |
|---|---|
int strncmpi(const char *s1, const char *s2, size_t n); |
用于比较两个字符串的前n个字符是否相等,忽略大小写 |
参数:
返回值:
s1 和 s2 代表的字符串相等(忽略大小写),则返回 0;s1 比 s2 小,则返回负数;s1 比 s2 大,则返回正数。1 |
|
注意: strncmpi 函数不是 C 语言标准库中的函数,但在某些编译器或操作系统中可能会提供。
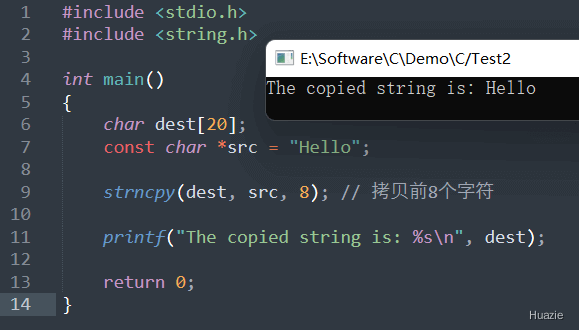
| 函数声明 | 函数功能 |
|---|---|
char *strncpy(char *dest, const char *src, size_t n); |
用于将一个字符串的一部分拷贝到另一个字符串中 |
参数:
1 |
|
当源字符串长度小于 n 时,strncpy() 函数将在目标字符串的末尾填充 \0 字符以达到指定的拷贝长度 n
1 |
|
如果源字符串长度大于等于 n 个字符,strncpy() 函数将会拷贝源字符串的前 n 个字符到目标字符串中,并且不会自动添加末尾的 \0 字符。这种情况下,目标字符串可能不是以 \0 字符结尾,因此需要手动在拷贝后的目标字符串中添加 \0 字符。
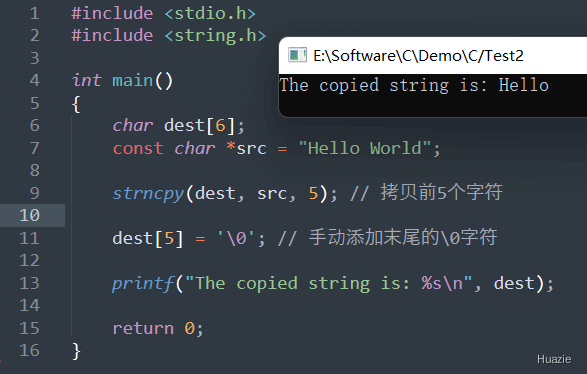
| 函数声明 | 函数功能 |
|---|---|
int strnicmp(const char *s1, const char *s2, size_t n); |
用于比较两个字符串的前n个字符是否相等,忽略大小写 |
参数:
返回值:
s1 和 s2 代表的字符串相等(忽略大小写),则返回 0;s1 比 s2 小,则返回负数;s1 比 s2 大,则返回正数。1 |
|
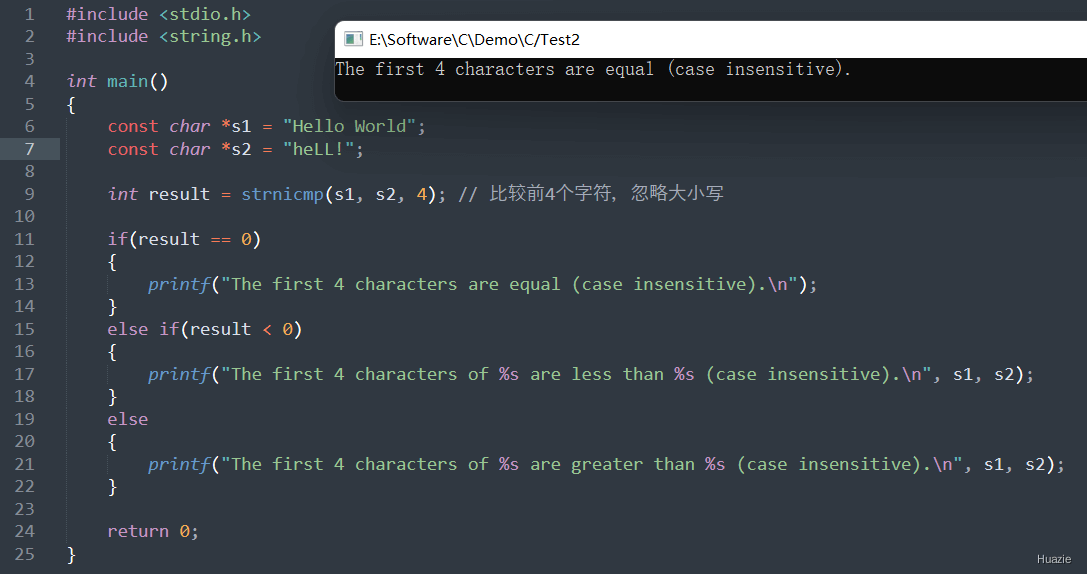
| 函数声明 | 函数功能 |
|---|---|
char *strnset(char *str, int c, size_t n); |
用于将一个字符串的前n个字符都设置为指定的字符 |
参数:
1 |
|
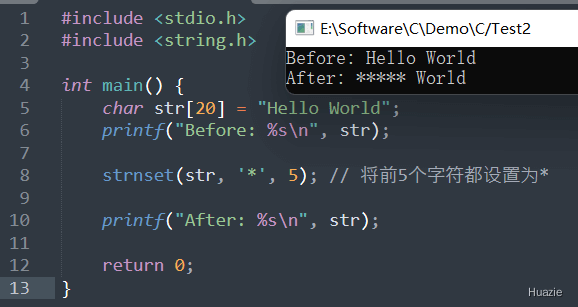
注意: strnset() 函数是非标准函数,并不是所有的编译器和操作系统都支持该函数。如果需要跨平台兼容,请使用标准库函数 memset() 来实现类似的功能
1 |
|
上述示例使用了标准库函数 memset 来将 str 的前 5 个字符都设置为 *
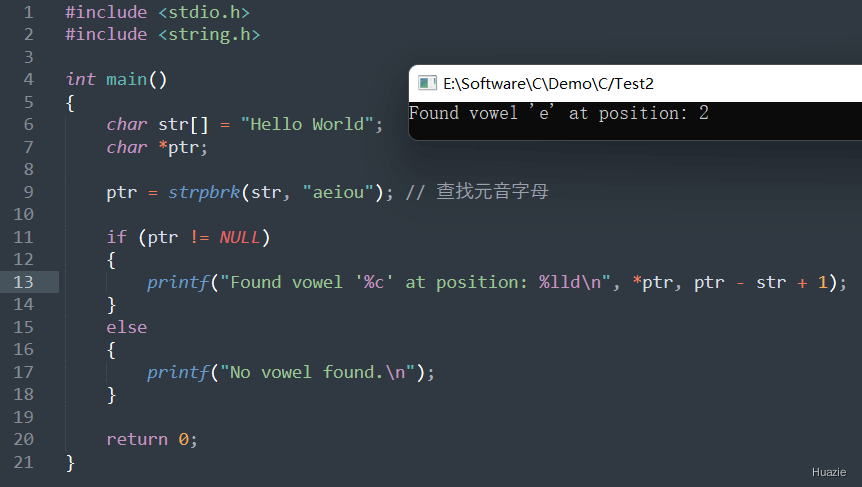
| 函数声明 | 函数功能 |
|---|---|
char *strpbrk(const char *str1, const char *str2); |
用于在一个字符串中查找任意给定字符集合中的字符的第一次出现位置 |
参数:
注意: 如果在str1中没有找到str2中的任何字符,则 strpbrk 函数返回NULL 指针
1 |
|
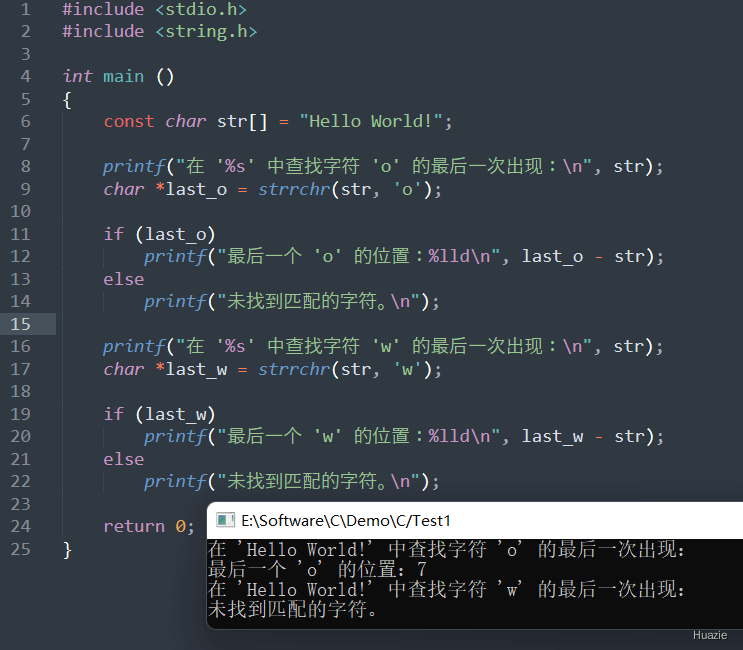
| 函数声明 | 函数功能 |
|---|---|
char *strrchr(const char *str, int character); |
在给定的字符串中查找指定字符的最后一个匹配项 |
参数:
返回值:
1 |
|
| 函数声明 | 函数功能 |
|---|---|
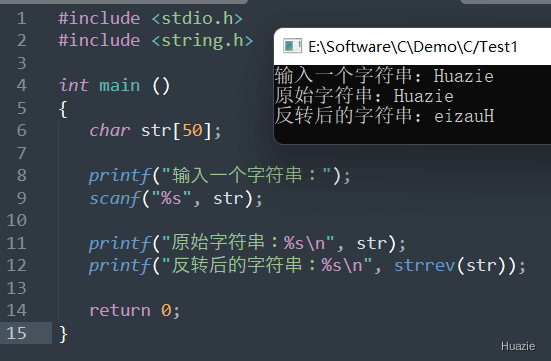
char *strrev(char *str); |
将给定字符串中的所有字符顺序颠倒,并返回颠倒后的字符串 |
参数:
注意:因为 strrev() 函数是一个非标准的库函数,许多编译器可能并不支持该函数,所以在使用该函数之前,请确保你的编译器支持它。
1 |
|
| 函数声明 | 函数功能 |
|---|---|
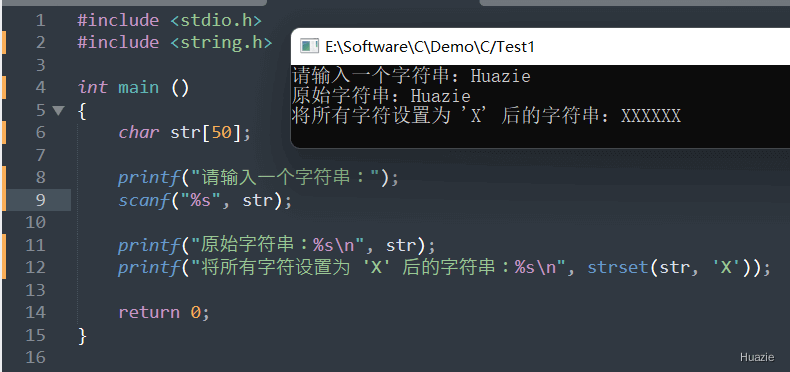
char *strset(char *str, int character); |
用于设置给定字符串中的所有字符为指定的值,并返回修改后的字符串 |
参数:
1 |
|
| 函数声明 | 函数功能 |
|---|---|
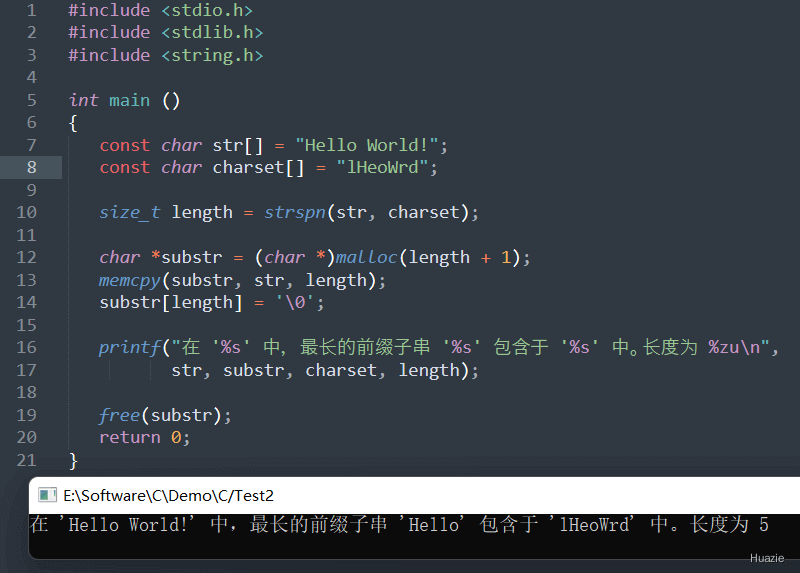
size_t strspn(const char *str1, const char *str2); |
计算字符串 str1 中包含在字符串 str2 中的前缀子字符串长度,并返回该长度值 |
参数:
1 |
|
上述示例代码运行后,如果出现 error: 'strndup' was not declared in this scope ,说明当前的编译器不支持 strndup() 函数。
因为 strndup() 函数是 C11 新增的函数,因此可能不是所有编译器都支持。
那我们就用如下的方式来替换一下 :
1 |
|
| 函数声明 | 函数功能 |
|---|---|
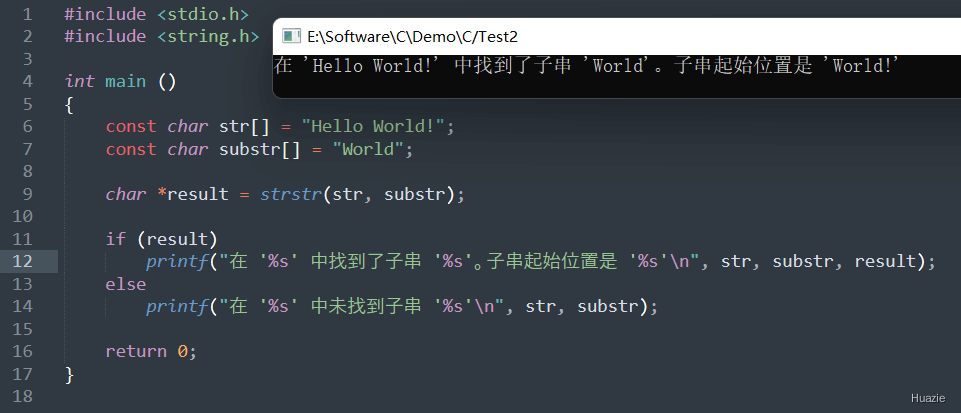
char *strstr(const char *str1, const char *str2); |
在字符串 str1 中查找第一个出现的字符串 str2,如果找到了,则返回指向该位置的指针;否则,返回 NULL |
参数:
1 |
|
| 函数声明 | 函数功能 |
|---|---|
double strtod(const char *str, char **endptr); |
将字符串 str 转换为一个浮点数(double 类型),并返回该浮点数。如果发生了转换错误,则返回 0.0,并且可以通过 endptr 指针返回指向第一个无法转换的字符的指针。 |
| 参数: |
1 |
|
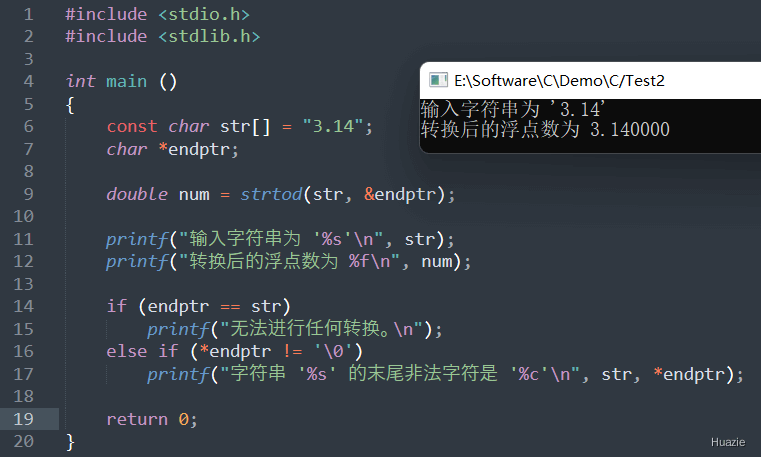
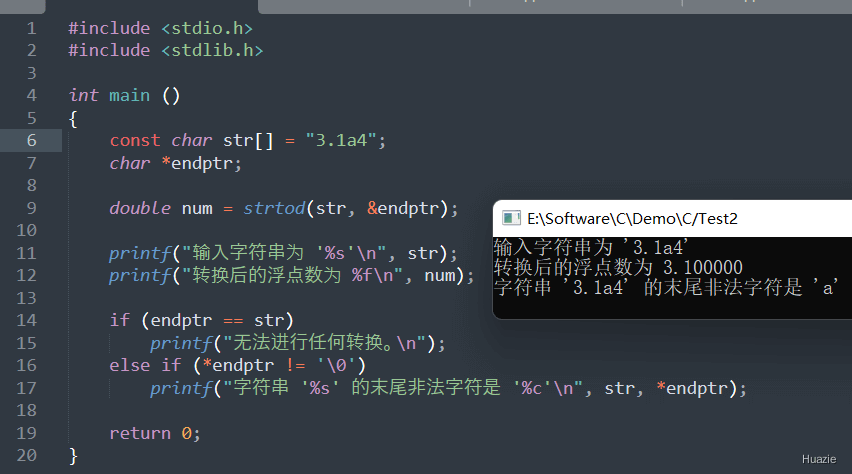
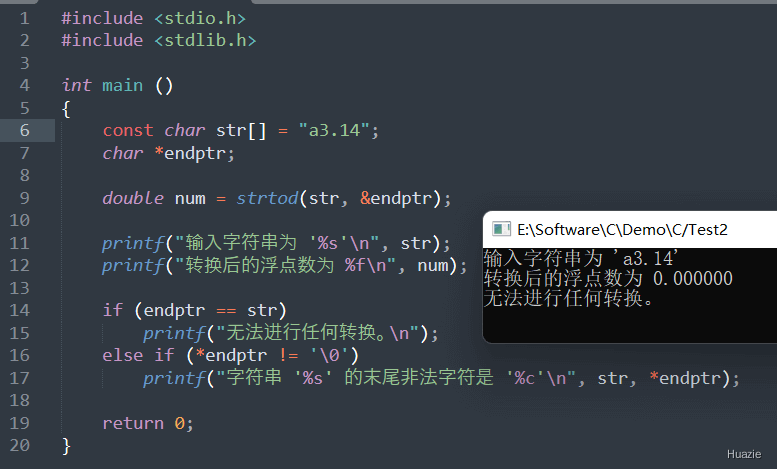
| 函数声明 | 函数功能 |
|---|---|
char *strtok(char *str, const char *delim); |
用于将一个字符串分割成多个子字符串 |
参数:
返回值: 分割后的第一个子字符串,并在每次调用时修改传入的原始字符串 str,使其指向下一个要被分割的子字符串
1 |
|
在上述的示例中,
str 和 字符集合 delim ;strtok() 函数将字符串 str 按照字符集合 delim 中的分隔符进行分割。每次调用 strtok() 函数时,它会返回分割出的第一个子字符串,并且会修改 str 指向下一个将要被分割的子字符串。strtok() 函数,并输出返回的每个子字符串,直到没有更多的子字符串可以分割为止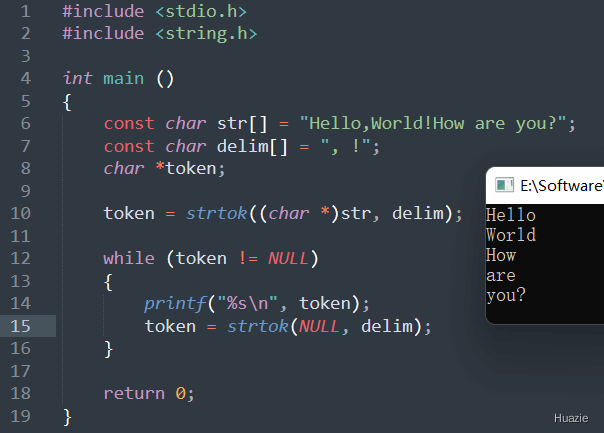
| 函数声明 | 函数功能 |
|---|---|
long int strtol(const char *str, char **endptr, int base); |
将字符串 str 转换为一个长整型数(long int 类型) |
参数:
2 到 36 之间的有效数字或者 0。为 0 表示采用默认的进制数,即可以解释成合法的整数的最大进制数(一般是 10)返回值:
0,并且可以通过 endptr 指针返回指向第一个无法转换的字符的指针。1 |
|
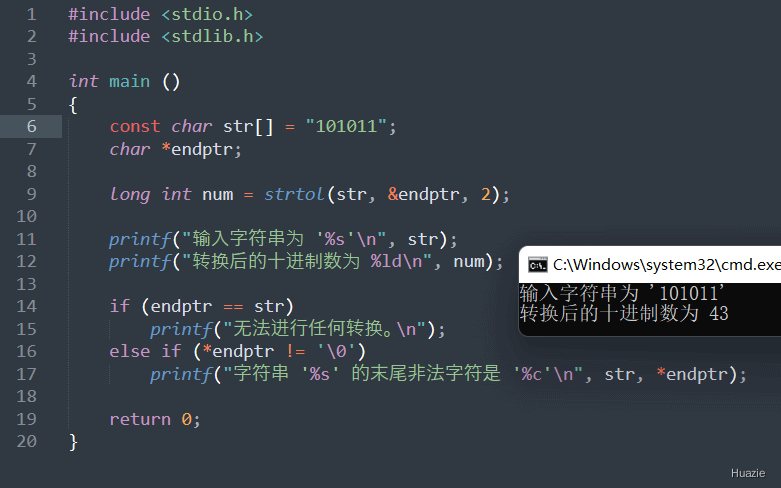
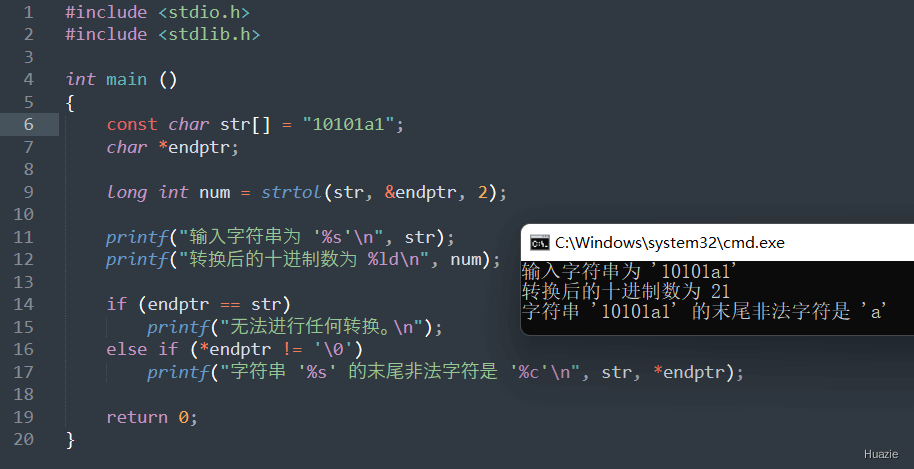
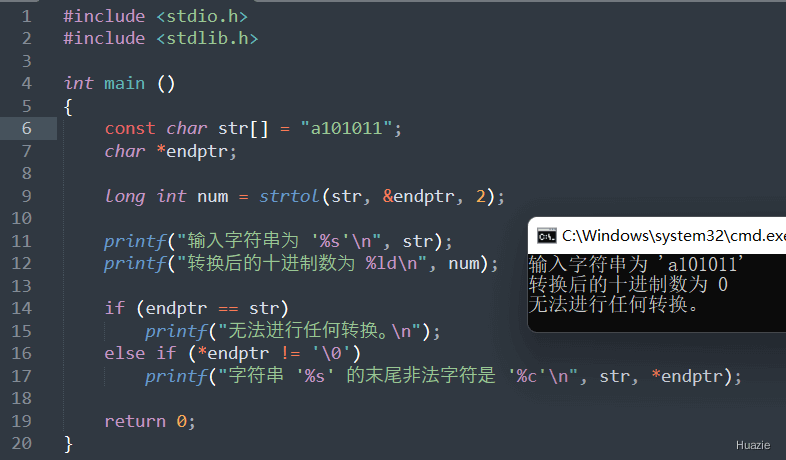
| 函数声明 | 函数功能 |
|---|---|
char *strupr(char *str); |
将字符串 str 中的所有小写字母转换为大写字母,并返回指向该字符串的指针 |
参数:
1 |
|

| 函数声明 | 函数功能 |
|---|---|
void swab(const void *src, void *dest, ssize_t nbytes); |
将源缓冲区中的每两个相邻字节进行互换,然后将结果存储到目标缓冲区中 |
参数:
1 |
|
上面示例中,我在一开始演示时,因为没有加上 #include <unistd.h> 这个头文件,导致出现如下错误:

| 函数声明 | 函数功能 |
|---|---|
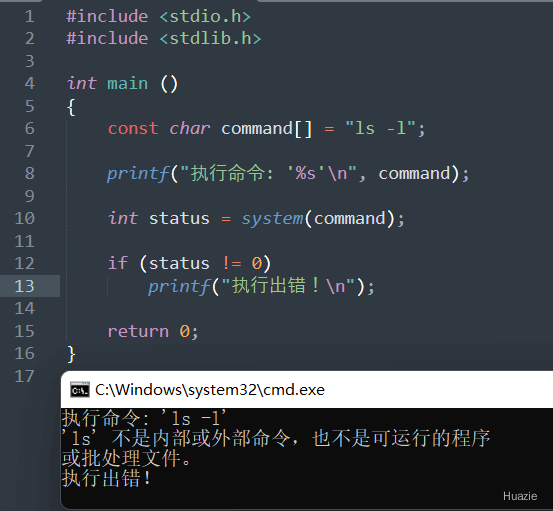
int system(const char *command); |
执行一个 shell 或 cmd 命令,并等待命令的完成 |
参数:
shell 或 cmd 命令。下面演示 执行 ls -l 的 shell 命令,笔者是在 windows环境下运行,故会出错,详见运行结果那里
1 |
|
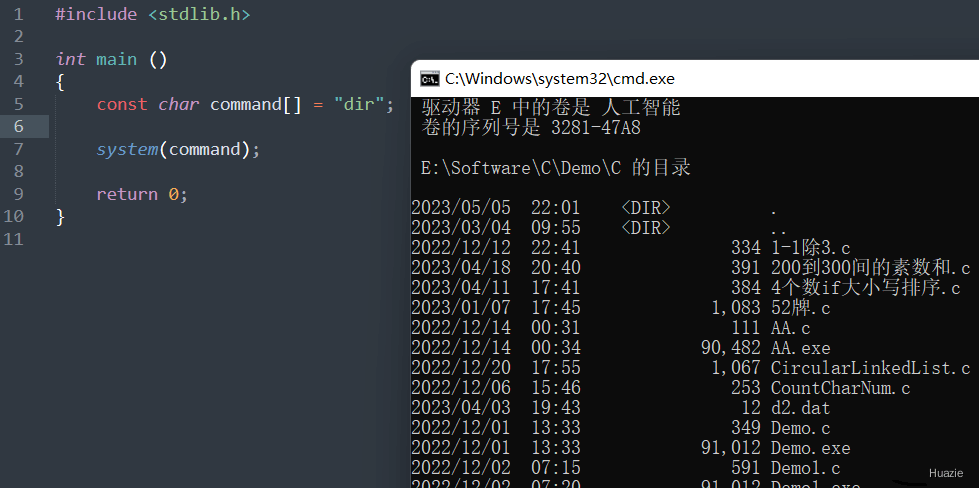
再来看下,演示使用 dir 命令,在 windows 下可以输出当前目录下的所有文件和子目录
1 |
|
![]()
| 函数声明 | 函数功能 |
|---|---|
unsigned int sleep(unsigned int seconds); |
它是 C 语言标准库中的函数,用于使当前进程挂起一定的时间。在挂起期间,操作系统会将该进程从调度队列中移除,直到指定的时间过去为止。 |
void Sleep(DWORD milliseconds); |
它是 Windows API 中的一部分,与 sleep 函数类似,它可以使当前线程挂起一段时间。 |
int sopen(const char* filename, int access, int sharemode, int shflag, ...); |
它是 Microsoft Visual C++ 中的一个函数,用于打开文件并返回文件句柄。与标准库中的 fopen 函数不同,sopen 函数支持以二进制方式打开文件,并且可以指定文件读写方式、共享模式和文件访问权限等参数。 |
void sound(int frequency); |
用于发出声音,sound 函数会持续发出声音,直到调用 nosound 函数停止 |
int spawnl(int mode, const char *cmdname, const char *arg0, ..., NULL); |
它是在 Windows 平台上使用的函数,用于启动另一个程序,并等待该程序运行结束后再继续执行本程序 |
int spawnle(int mode, const char *cmdname, const char *arg0, ..., const char *envp[]); |
它是在 Windows 平台上使用的函数,可以启动另一个程序,并通过指定的环境变量传递参数 |
int sprintf(char *str, const char *format, ...); |
用于将格式化的字符串输出到指定的缓冲区中 |
int snprintf(char *str, size_t size, const char *format, ...); |
用于将格式化的字符串输出到指定的缓冲区中,类似于 sprintf 函数,但它可以限制输出字符串的长度,避免缓冲区溢出 |
double sqrt(double x); |
计算 x 的平方根(double) |
float sqrtf(float x); |
计算 x 的平方根 (float) |
long double sqrtl(long double x); |
计算 x 的平方根 (long double) |
void srand(unsigned int seed); |
用于初始化伪随机数生成器 |
int sscanf(const char *str, const char *format, ...); |
用于从字符串中读取数据并进行格式化转换 |
int stat(const char *path, struct stat *buf); |
用于获取文件或目录的属性信息,例如文件大小、创建时间、修改时间等。这些属性信息都被保存在一个名为 struct stat 的结构体中。 |
int stime(const time_t *t); |
它是是 Unix/Linux 系统中的一个系统调用函数,用于设置系统时间 |
char *stpcpy(char *dest, const char *src); |
用于复制一个字符串到另一个字符串缓冲区,并返回目标字符串的结尾指针 |
char* strcat(char* dest, const char* src); |
用于将一个字符串拼接到另一个字符串的末尾 |
char* strchr(const char* str, int c); |
用于查找字符串中第一次出现指定字符的位置,并返回该位置的指针 |
int strcmp(const char* str1, const char* str2); |
用于比较两个字符串是否相等 |
char* strcpy(char* dest, const char* src); |
用于将一个字符串复制到另一个字符串缓冲区中 |
size_t strcspn(const char* str, const char* charset); |
用于查找字符串中第一次出现指定字符集合中任何字符的位置,并返回该位置的索引 |
| 函数声明 | 函数功能 |
|---|---|
unsigned int sleep(unsigned int seconds); |
它是 C 语言标准库中的函数,用于使当前进程挂起一定的时间。在挂起期间,操作系统会将该进程从调度队列中移除,直到指定的时间过去为止。 |
void Sleep(DWORD milliseconds); |
它是 Windows API 中的一部分,与 sleep 函数类似,它可以使当前线程挂起一段时间。 |
sleep 函数参数:
Sleep 函数参数:
1 |
|
在使用 sleep() 函数时,将会使当前线程或者进程暂停指定的时间,以便给其他进程或线程执行机会,同时也可以用来控制程序的运行速度。
虽然 sleep() 函数很简单,但是需要注意以下几点:
sleep() 的精度并不高,它所挂起的时间可能会略微超过要求的时间。sleep() 函数是阻塞式的,即在调用 sleep() 函数期间,该进程不能进行任何其他操作,包括响应信号等。sleep() 函数期间,如果发生信号,那么 sleep() 函数将被中断,该进程将继续运行。1 |
|
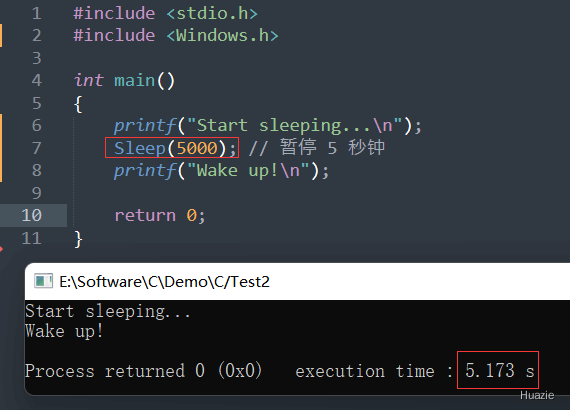
由于 Sleep() 函数是阻塞式的,因此该函数调用期间,当前线程将被阻塞。在函数调用结束后,该线程将恢复运行。
在 Windows 系统下使用 Sleep() 函数时,需要注意以下几点:
Sleep() 函数以毫秒为单位指定时间,精度比 sleep() 函数更高。Sleep() 函数期间,当前线程将被阻塞,不能进行任何其他操作,包括响应信号等。Sleep() 函数期间,如果发生信号,那么 Sleep() 函数将被中断,该线程将继续运行。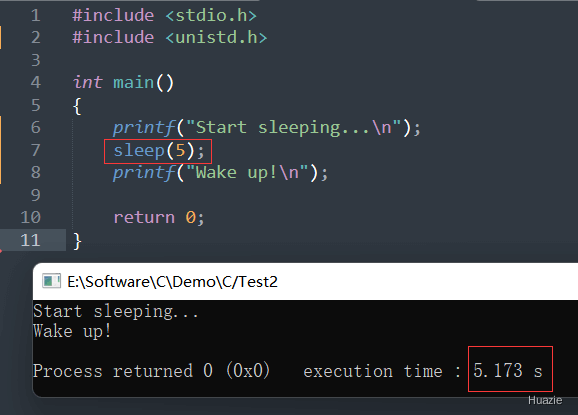
| 函数声明 | 函数功能 |
|---|---|
int sopen(const char* filename, int access, int sharemode, int shflag, ...); |
它是 Microsoft Visual C++ 中的一个函数,用于打开文件并返回文件句柄。与标准库中的 fopen 函数不同,sopen 函数支持以二进制方式打开文件,并且可以指定文件读写方式、共享模式和文件访问权限等参数。 |
参数:
_O_RDONLY:只读方式打开文件_O_WRONLY:只写方式打开文件_O_RDWR:读写方式打开文件_O_APPEND:在文件末尾追加数据_O_CREAT:如果文件不存在,则创建文件_O_TRUNC:如果文件已存在,清空文件内容_O_EXCL:与 _O_CREAT 配合使用,如果文件已经存在则打开失败_SH_DENYRW:独占方式打开文件,其他进程不能读取或写入该文件_SH_DENYWR:共享读取方式打开文件,其他进程不能写入该文件_SH_DENYRD:共享写入方式打开文件,其他进程不能读取该文件_SH_DENYNO:共享方式打开文件,其他进程可以读取和写入该文件_S_IWRITE:文件可写_S_IREAD:文件可读_O_CREAT 参数,则需要指定文件的访问权限1 |
|
指定文件共享模式,如果没有对应的宏常量,则可以定义如下:
1 |
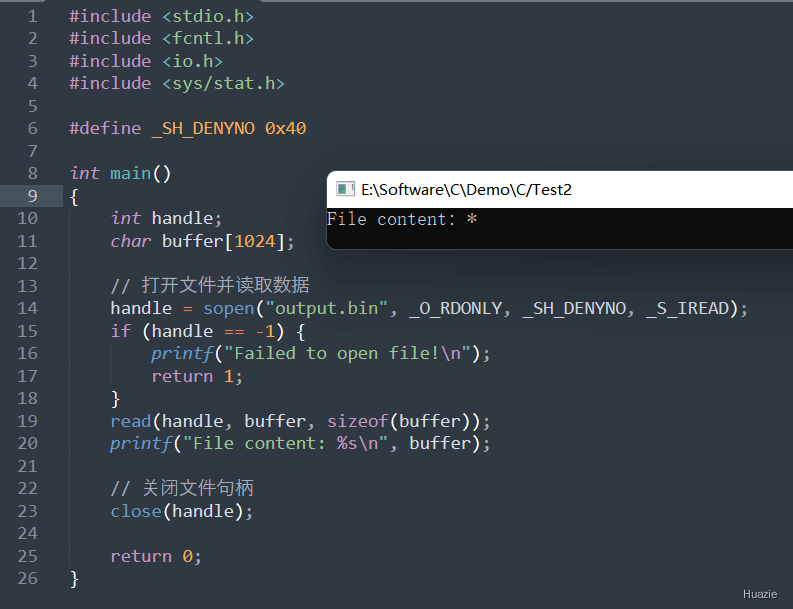
| 函数声明 | 函数功能 |
|---|---|
void sound(int frequency); |
用于发出声音 |
void nosound(void); |
sound 函数会持续发出声音,直到调用 nosound 函数停止 |
参数:
1 |
|
Windows 下如果上述出现 error: 'sound' was not declared in this scope,可以使用如下:
1 |
|
注意: 在 Windows 平台上建议使用 Beep() 函数代替 sound() 函数,因为 Beep() 函数不需要特殊的硬件支持,并且可移植性更好。
| 函数声明 | 函数功能 |
|---|---|
int spawnl(int mode, const char *cmdname, const char *arg0, ..., NULL); |
它是在 Windows 平台上使用的函数,用于启动另一个程序,并等待该程序运行结束后再继续执行本程序 |
参数:
P_WAIT 或 P_NOWAITNULL 结尾1 |
|
1 |
|
如果在使用 spawnl() 函数时遇到了 "Error from spawnl: Invalid argument" 错误,有可能是由于参数传递不正确或要执行的程序不存在等原因导致的。
以下是一些可能导致该错误的情况:
cmdname 参数包含非法字符或格式不正确。NULL 结尾。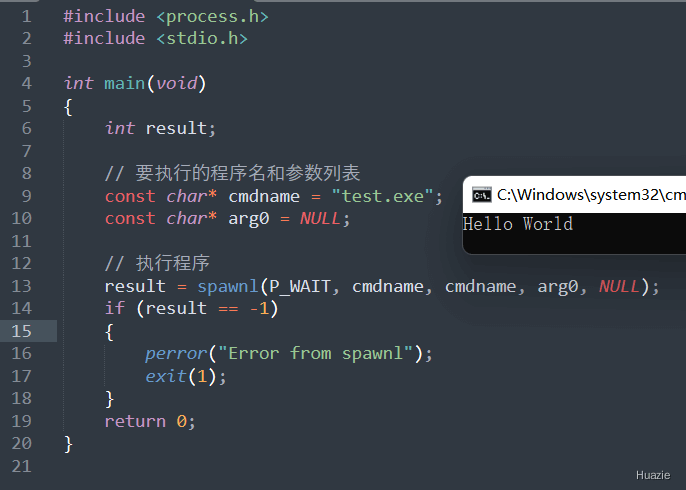
| 函数声明 | 函数功能 |
|---|---|
int spawnle(int mode, const char *cmdname, const char *arg0, ..., const char *envp[]); |
它是在 Windows 平台上使用的函数,可以启动另一个程序,并通过指定的环境变量传递参数 |
参数:
P_WAIT 或 P_NOWAITNULL 结尾1 |
|
1 |
|
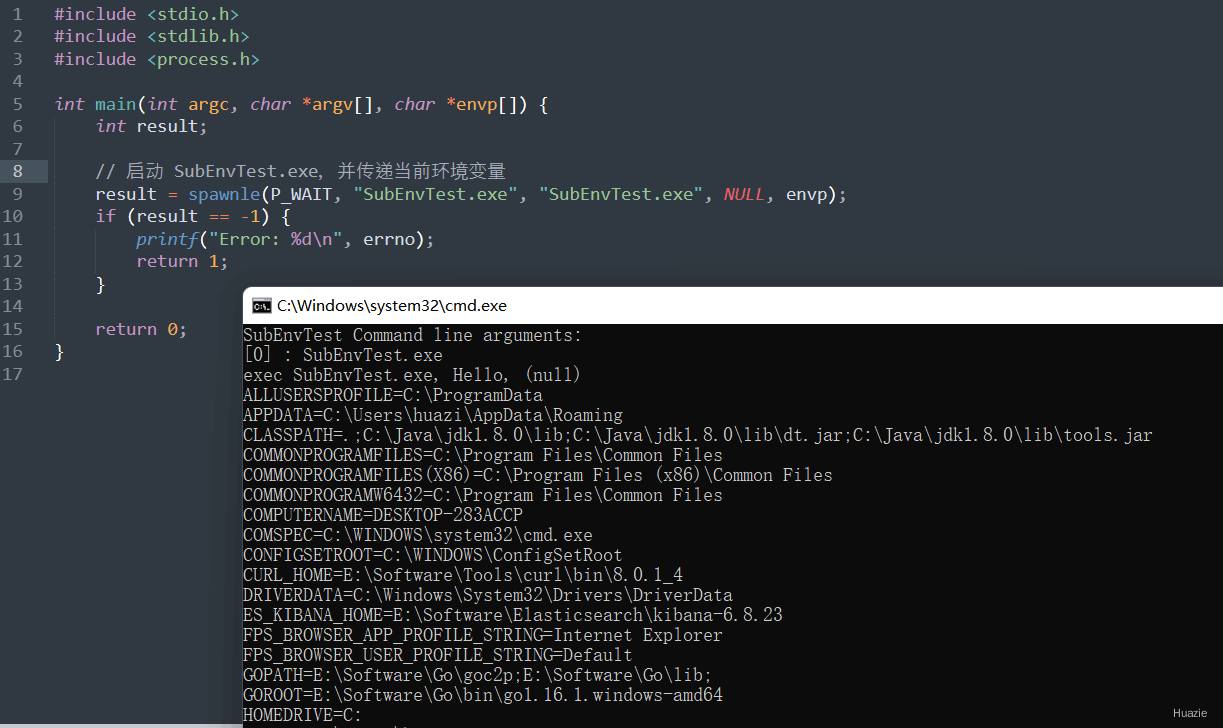
| 函数声明 | 函数功能 |
|---|---|
int sprintf(char *str, const char *format, ...); |
用于将格式化的字符串输出到指定的缓冲区中 |
参数:
1 |
|
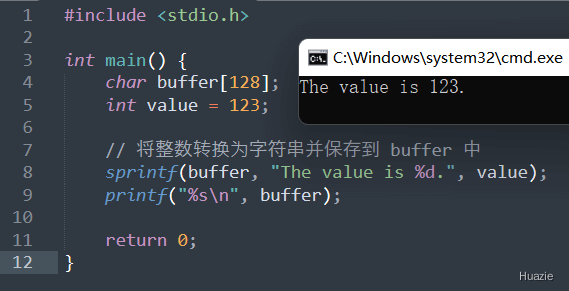
| 函数声明 | 函数功能 |
|---|---|
int snprintf(char *str, size_t size, const char *format, ...); |
用于将格式化的字符串输出到指定的缓冲区中,类似于 sprintf 函数,但它可以限制输出字符串的长度,避免缓冲区溢出 |
参数:
1 |
|
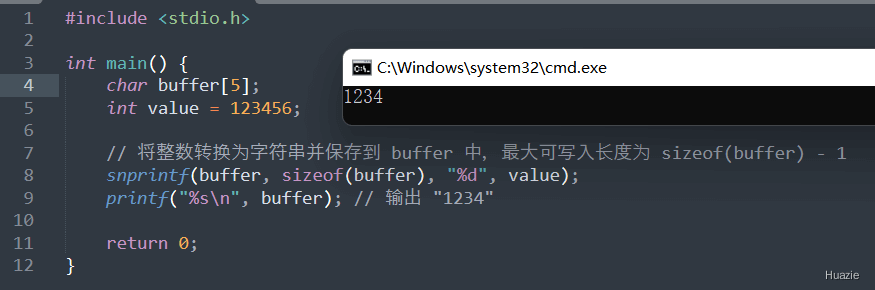
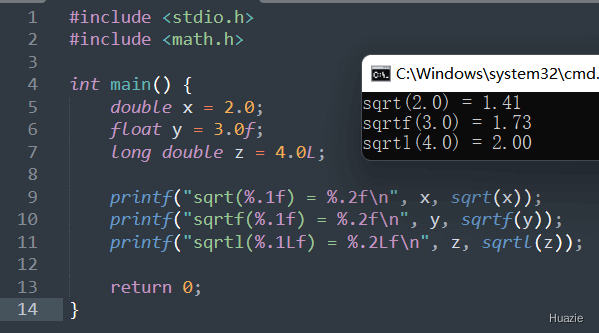
| 函数声明 | 函数功能 |
|---|---|
double sqrt(double x); |
计算 x 的平方根(double) |
float sqrtf(float x); |
计算 x 的平方根 (float) |
long double sqrtl(long double x); |
计算 x 的平方根 (long double) |
参数:
1 |
|
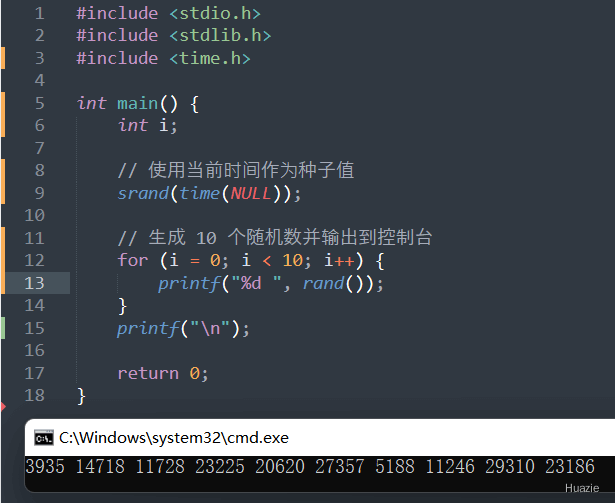
| 函数声明 | 函数功能 |
|---|---|
void srand(unsigned int seed); |
用于初始化伪随机数生成器 |
参数:
1 |
|
注意: 如果不设置种子值,则每次程序运行时都会得到相同的随机数序列。因此,我们在实际开发中,常常使用时间戳或其他随机值来作为种子值,以确保生成的随机数具有更好的随机性。
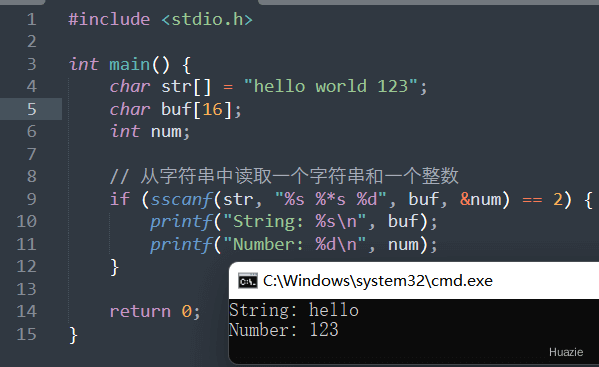
| 函数声明 | 函数功能 |
|---|---|
int sscanf(const char *str, const char *format, ...); |
用于从字符串中读取数据并进行格式化转换 |
参数:
1 |
|
在上述的示例代码中,我们使用 sscanf() 函数从字符串 "hello world 123" 中读取一个字符串和一个整数,并输出到控制台。
注意: 在格式字符串中,%s 表示读取一个字符串,%d 表示读取一个整数。另外,%*s 表示读取并忽略一个字符串。
| 函数声明 | 函数功能 |
|---|---|
int stat(const char *path, struct stat *buf); |
用于获取文件或目录的属性信息,例如文件大小、创建时间、修改时间等。这些属性信息都被保存在一个名为 struct stat 的结构体中。 |
参数:
struct stat 结构体的指针,用于存储获取到的属性信息返回值:
0;-1 并设置相应的错误码(存储在 errno 变量中)1 |
|
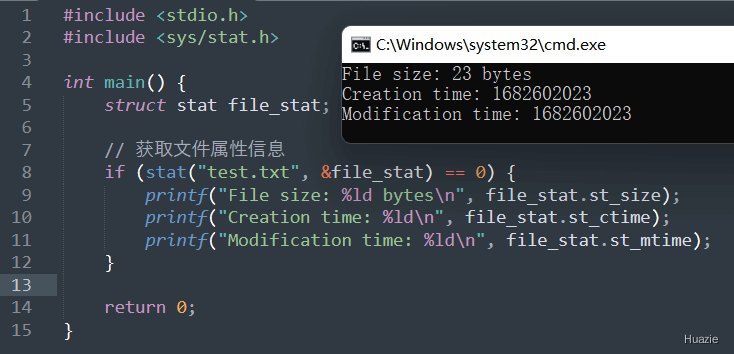
| 函数声明 | 函数功能 |
|---|---|
int stime(const time_t *t); |
它是是 Unix/Linux 系统中的一个系统调用函数,用于设置系统时间 |
参数:
返回值:
0;-1 并设置相应的错误码(存储在 errno 变量中)1 |
|
在如上的示例代码中,
time() 函数获取当前时间,并输出到控制台;2022 年 1 月 1 日,并等待一秒钟以确保时间设置完成。注意: stime() 函数只能在 Linux/Unix 系统上使用,并且需要 root 权限才能调用。另外,在修改系统时间时应谨慎行事,以避免对系统和应用程序造成不可预料的影响。
| 函数声明 | 函数功能 |
|---|---|
char *stpcpy(char *dest, const char *src); |
用于复制一个字符串到另一个字符串缓冲区,并返回目标字符串的结尾指针 |
参数:
返回值: 一个指向目标字符串结尾的指针
1 |
|
在上述的示例代码中,我们使用 stpcpy() 函数将源字符串 "Hello world" 复制到目标字符串 dest 中,并输出两个字符串以及目标字符串的结尾指针。
注意: stpcpy() 函数只能在支持 ISO C99 或 POSIX.1-2001 标准的系统上使用,对于其他系统,可能需要使用 strcpy() 函数代替。此外,应始终确保目标字符串缓冲区具有足够的空间来存储源字符串,以避免发生缓冲区溢出。
| 函数声明 | 函数功能 |
|---|---|
char* strcat(char* dest, const char* src); |
用于将一个字符串拼接到另一个字符串的末尾 |
参数:
返回值: 一个指向目标字符串结尾的指针
1 |
|
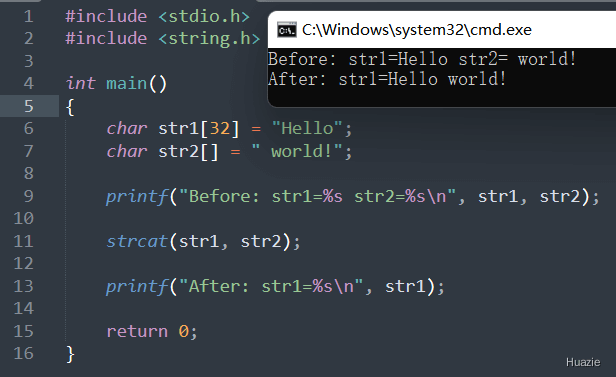
| 函数声明 | 函数功能 |
|---|---|
char* strchr(const char* str, int c); |
用于查找字符串中第一次出现指定字符的位置,并返回该位置的指针 |
参数:
1 |
|
注意: strchr() 函数只能查找单个字符,如果要查找一个子字符串,应使用 strstr() 函数代替。另外,在查找字符时,需要将字符转换为整数值传递给 strchr() 函数,以避免发生类型错误。
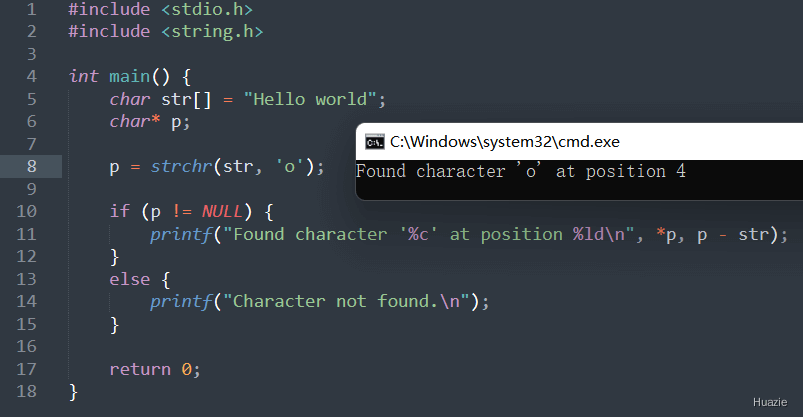
| 函数声明 | 函数功能 |
|---|---|
int strcmp(const char* str1, const char* str2); |
用于比较两个字符串是否相等 |
参数:
返回值: 一个整数,表示两个字符串之间的大小关系
str1 小于 str2,则返回负整数;str1 大于 str2,则返回正整数;str1 等于 str2,则返回 0。1 |
|
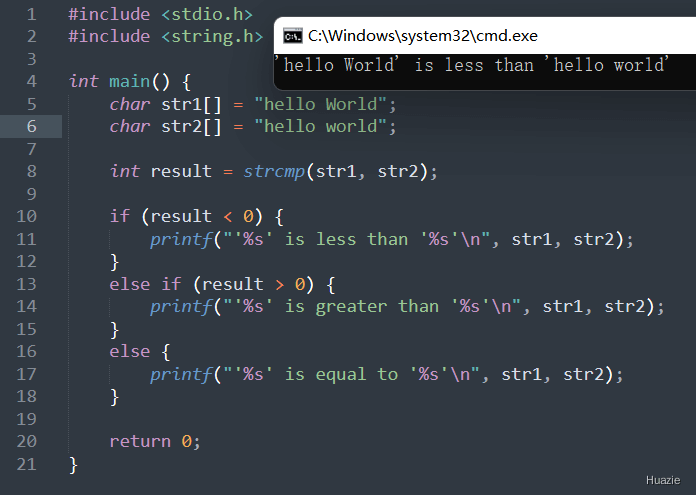
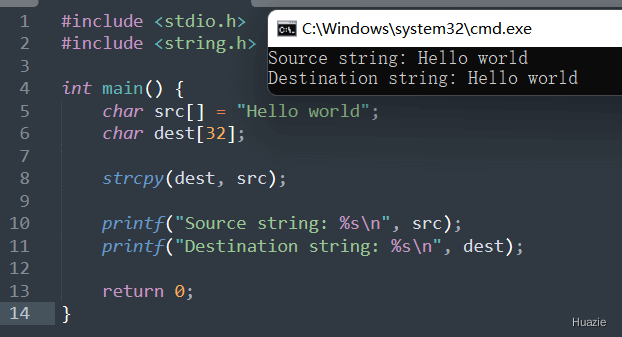
| 函数声明 | 函数功能 |
|---|---|
char* strcpy(char* dest, const char* src); |
用于将一个字符串复制到另一个字符串缓冲区中 |
参数:
返回值: 一个指向目标字符串结尾的指针
1 |
|
注意: strcpy() 函数只能用于复制以 \0 结尾的字符串,否则可能导致未定义的行为或内存损坏。在调用 strcpy() 函数之前,应确保目标字符串缓冲区具有足够的空间来容纳源字符串,以避免发生缓冲区溢出。
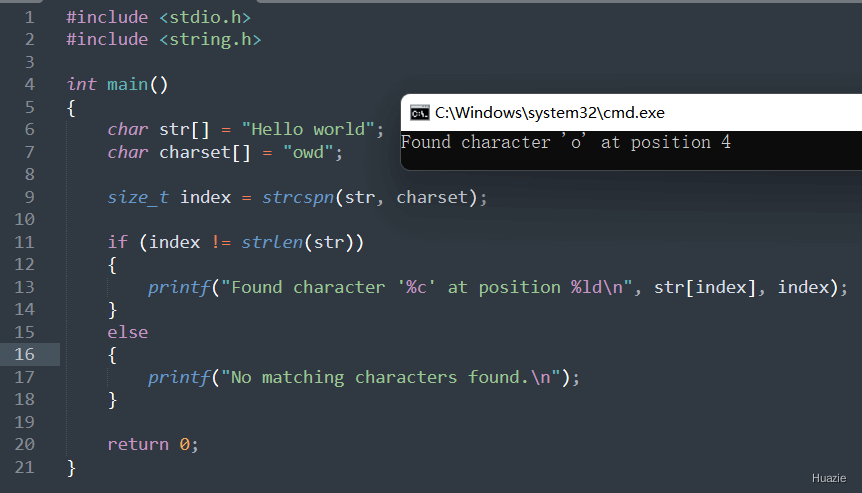
| 函数声明 | 函数功能 |
|---|---|
size_t strcspn(const char* str, const char* charset); |
用于查找字符串中第一次出现指定字符集合中任何字符的位置,并返回该位置的索引 |
参数:
1 |
|
在上述的示例代码中,我们使用 strcspn() 函数在字符串 "Hello world" 中查找字符集合 "owd" 中的任何字符,并输出找到的字符及其在字符串中的位置索引。
![]()
| 函数声明 | 函数功能 |
|---|---|
void setlinestyle( int linestyle, unsigned upattern, int thickness ); |
设置当前绘图窗口的线条样式、线型模式和线条宽度 |
void *setmem(void *dest, size_t n, int c); |
用于将指定内存区域的每个字节都设置为指定的值 |
int setmode(int fd, int mode); |
它是 Windows 系统下的特定库函数,用于将指定文件的 I/O 模式设置为文本模式或二进制模式 |
void setpalette(int colornum, int color); |
设置调色板的颜色 |
void setrgbpalette(int colornum, int red, int green, int blue); |
用于设置当前绘图窗口的调色板中某个颜色的 RGB 值 |
void settextjustify(int horiz, int vert); |
用于设置文本输出的对齐方式 |
void settextstyle(int font, int direction, int charsize); |
用于设置当前文本输出的字体、方向和大小 |
void settime(struct time *timep); |
设置当前系统时间 |
void setusercharsize(int multx, int dirx, int multy, int diry); |
用于设置用户定义的字符大小 |
int setvbuf(FILE *stream, char *buf, int type, unsigned size); |
用于设置文件流的缓冲方式 |
void setviewport(int left, int top, int right, int bottom, int clipflag); |
用于设置绘图窗口的视口范围 |
void setvisualpage(int pagenum); |
用于设置图形窗口中用户可见的页面 |
void setwritemode(int mode); |
用于设置绘画操作的写入模式 |
void (*signal(int signum, void (*handler)(int)))(int); |
用于设置指定信号的处理方式。当系统接收到某个信号时,会调用相应的信号处理函数来处理该信号。在调用 signal 函数时,需要指定要处理的信号以及相应的信号处理函数。 |
double sin(double x); |
用于计算一个角度(以弧度为单位)的正弦值(double) |
float sinf(float x); |
用于计算一个角度(以弧度为单位)的正弦值(float) |
long double sinl(long double x); |
用于计算一个角度(以弧度为单位)的正弦值(long double) |
void sincos(double x, double* sinVal, double* cosVal); |
用于同时计算一个角度(以弧度为单位)的正弦值和余弦值 |
void sincosf(float x, float* sinVal, float* cosVal); |
用于同时计算一个角度(以弧度为单位)的正弦值和余弦值 |
void sincosl(long double x, long double* sinVal, long double* cosVal); |
用于同时计算一个角度(以弧度为单位)的正弦值和余弦值 |
double sinh(double x); |
用于计算一个数的双曲正弦值 |
float sinhf(float x); |
用于计算一个数的双曲正弦值 |
long double sinhl(long double x); |
用于计算一个数的双曲正弦值 |
| 函数声明 | 函数功能 |
|---|---|
void setlinestyle( int linestyle, unsigned upattern, int thickness ); |
设置当前绘图窗口的线条样式、线型模式和线条宽度 |
参数:
16 位的无符号整数,用二进制位表示线型模式,其中 1 表示绘制线条,0 表示空白。例如,如果 upattern 的值是 0x00FF,则表示绘制一段线条,然后空白一段,重复这个过程直到结束。如果 upattern 的值是 0x5555,则表示绘制一段虚线。| 线条样式 | 值 | 描述 |
|---|---|---|
| SOLID_LINE | 0 | 实线 |
| DOTTED_LINE | 1 | 虚线 |
| CENTER_LINE | 2 | 点线 |
| DASHED_LINE | 3 | 长短线 |
| USERBIT_LINE | 4 | 双点线 |
1 |
|
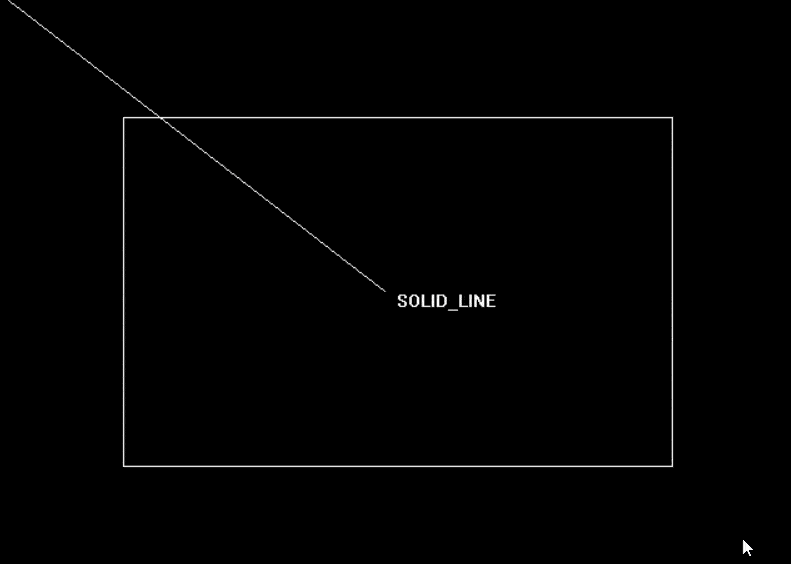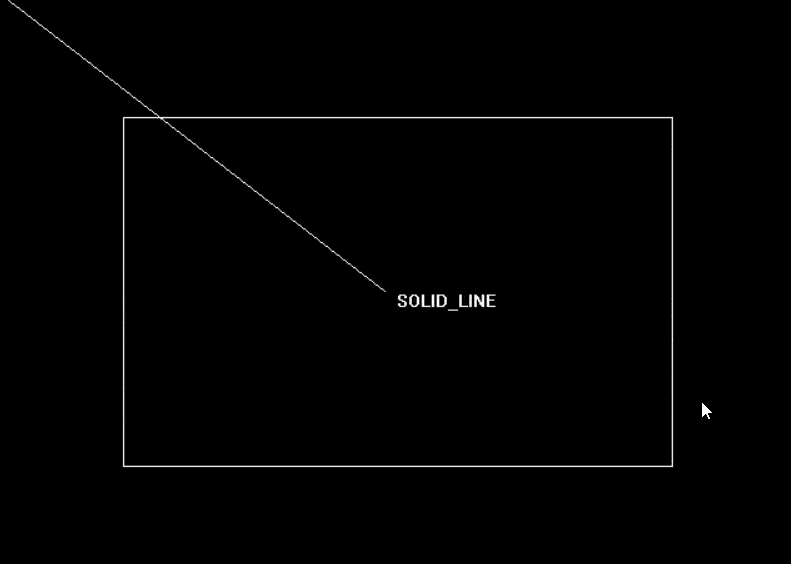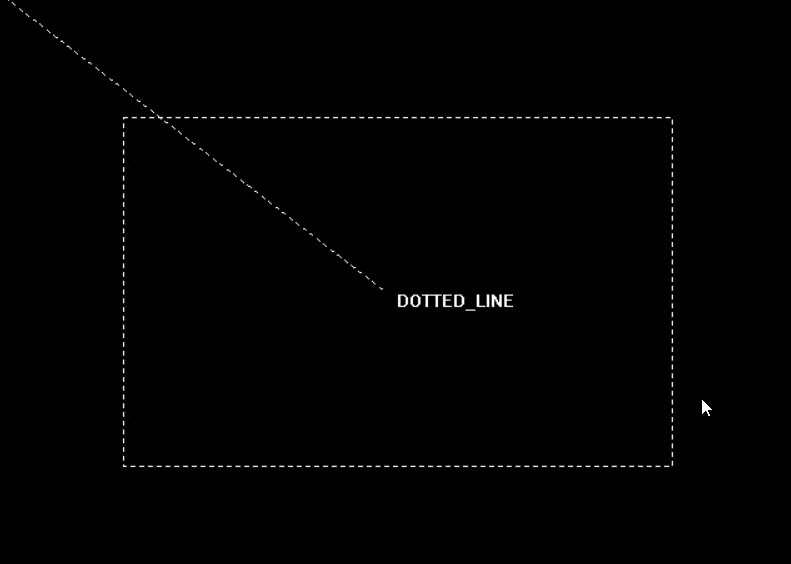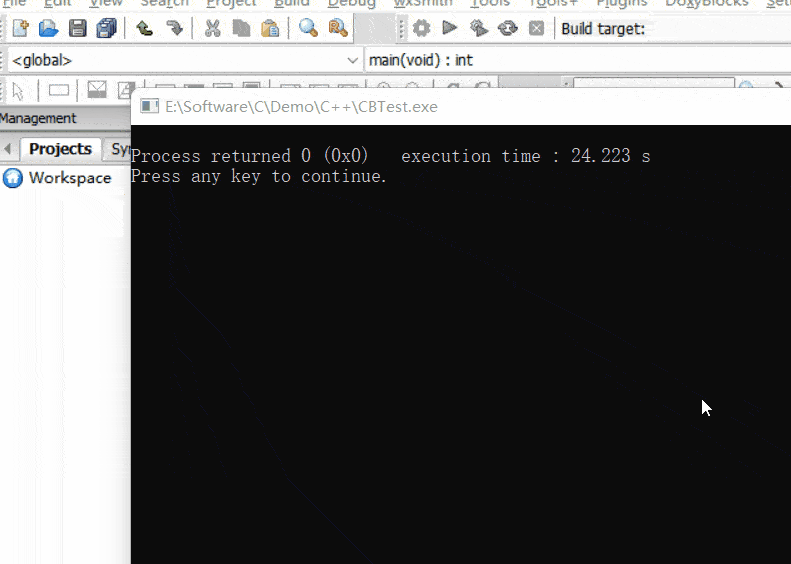
| 函数声明 | 函数功能 |
|---|---|
void *setmem(void *dest, size_t n, int c); |
用于将指定内存区域的每个字节都设置为指定的值 |
参数:
·注意: setmem() 并不是标准 C 函数,而是 POSIX 标准库函数,因此可能并不被所有平台所支持。如果您的编译器或操作系统不支持 setmem() 函数,可以使用标准 C 库函数 memset() 来代替
1 |
|
在上面的示例程序中,
malloc() 函数分配了 10 字节的内存空间,并将其赋值给指针变量 str。setmem() 函数将 str 指向的内存区域的每个字节都设置为 'A'。str 的内容并使用 free() 函数释放了分配的内存空间。| 函数声明 | 函数功能 |
|---|---|
int setmode(int fd, int mode); |
它是 Windows 系统下的特定库函数,用于将指定文件的 I/O 模式设置为文本模式或二进制模式 |
参数:
fileno() 函数将文件指针转换为文件描述符_O_BINARY:二进制模式_O_TEXT:文本模式注意: 在 Windows 系统中,文本模式和二进制模式之间的区别在于换行符的处理方式。在文本模式下,Windows 将回车符(\r)和换行符(\n)组成的字符序列映射为单个换行符(\n),因此在读取文本文件时可以正确处理换行符。在二进制模式下,Windows 不对回车符和换行符做任何转换,因此在读取文本文件时可能会出现问题。
1 |
|
在上面的示例程序中,我们首先使用 setmode() 函数将标准输入流的模式从二进制模式切换到文本模式;如果调用成功,则返回 0,否则返回 -1,并将错误信息存储在全局变量 errno 中。在程序中,我们使用 perror() 函数来输出错误信息。如果调用成功,则输出一条提示信息。
注意: setmode() 函数只适用于 Windows 系统下的 C/C++ 编程,并且不是标准库函数,因此在跨平台编程时应该避免使用它。在 Unix/Linux 系统下,也可以使用 fcntl() 函数来设置文件描述符的模式。
| 函数声明 | 函数功能 |
|---|---|
void setpalette(int colornum, int color); |
设置调色板的颜色 |
参数:
RGB 值,也可以是一个预定义颜色名称,例如 RED 或 BLUE。1 |
|
| 函数声明 | 函数功能 |
|---|---|
void setrgbpalette(int colornum, int red, int green, int blue); |
用于设置当前绘图窗口的调色板中某个颜色的 RGB 值 |
参数:
0~255。RGB 值,取值范围为 0~255。1 |
|
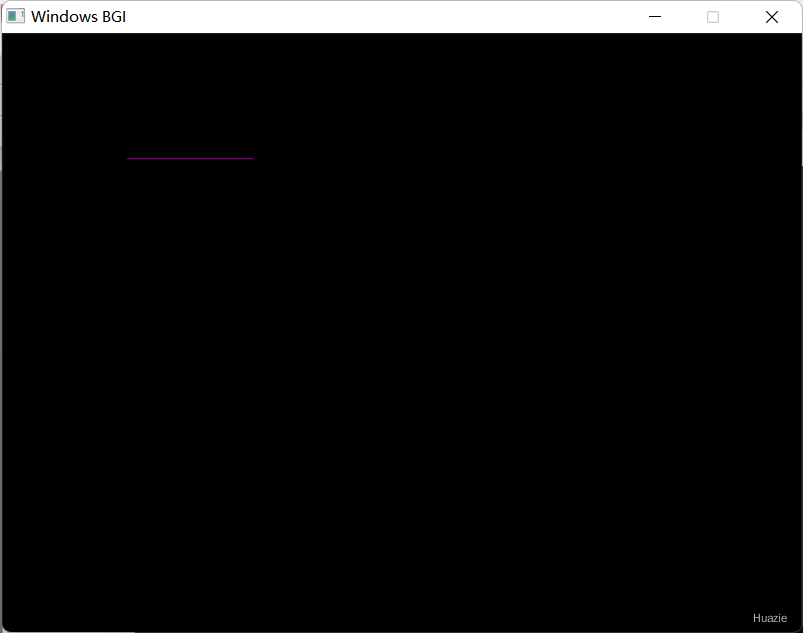
在上述的这个示例程序中,
setbkcolor() 函数设置背景颜色为白色,然后清除原有屏幕使前面设置生效。setrgbpalette() 函数将第 5 种颜色设置为蓝绿色,并使用 setcolor() 函数将绘图颜色设为索引值 5(即蓝绿色);line() 函数绘制了一条斜线。
| 函数声明 | 函数功能 |
|---|---|
void settextjustify(int horiz, int vert); |
用于设置文本输出的对齐方式 |
参数:
LEFT_TEXT:左对齐CENTER_TEXT:居中对齐RIGHT_TEXT:右对齐TOP_TEXT:顶部对齐CENTER_TEXT:居中对齐BOTTOM_TEXT:底部对齐1 |
|
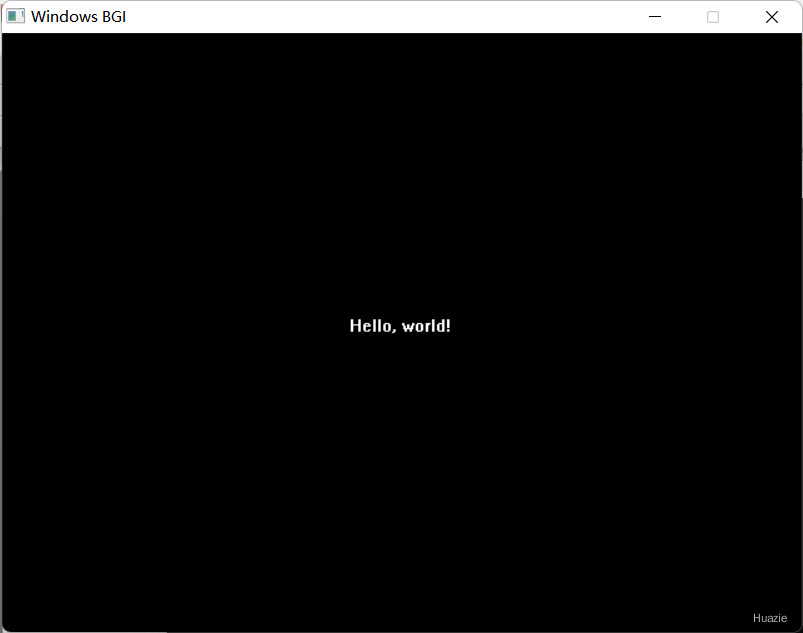
在上述的示例程序中,我们使用 settextjustify() 函数将文本输出的对齐方式设置为居中对齐,然后使用 outtextxy() 函数在窗口的中心输出一行文本。
注意: 在使用 settextjustify() 函数设置对齐方式时,必须指定正确的参数值,并且同时考虑水平和垂直方向的对齐方式,否则可能会导致文本输出位置错误。
| 函数声明 | 函数功能 |
|---|---|
void settextstyle(int font, int direction, int charsize); |
用于设置当前文本输出的字体、方向和大小 |
参数:
DEFAULT_FONT:默认字体TRIPLEX_FONT:粗体三线字体SMALL_FONT:小号字体SANS_SERIF_FONT:无衬线字体GOTHIC_FONT:哥特式字体SCRIPT_FONT:手写字体HORIZ_DIR:水平方向(从左到右)VERT_DIR:垂直方向(从下到上)DEFAULT_WIDTH 和 DEFAULT_HEIGHT:默认大小TRIPLEX_WIDTH 和 TRIPLEX_HEIGHT:大号尺寸SMALL_WIDTH 和 SMALL_HEIGHT:小号尺寸1 |
|
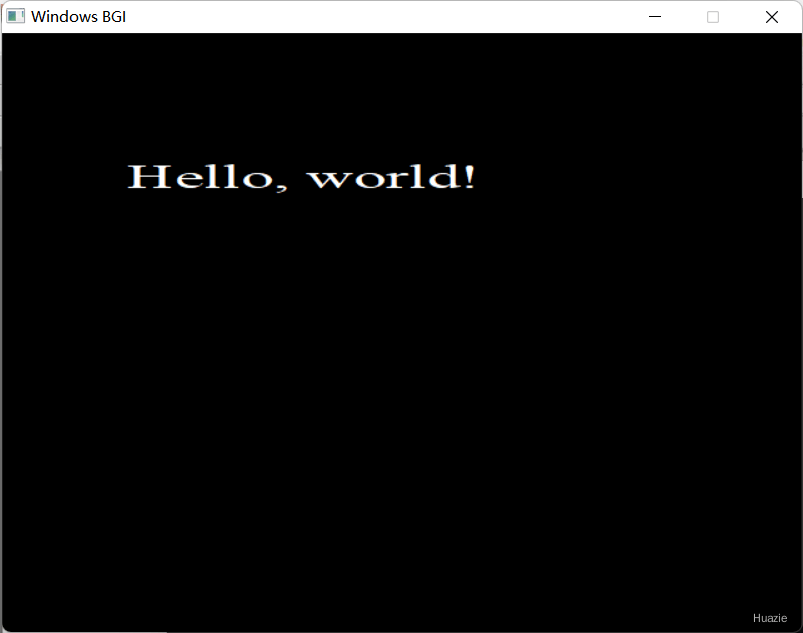
在上述的示例程序中,我们使用 settextstyle() 函数将文本输出的字体设置为粗体三线字体、方向设置为水平方向、大小设置为大号尺寸,然后使用 outtextxy() 函数在窗口的指定位置输出一行文本。
注意: 在使用 settextstyle() 函数设置文本样式时,必须指定正确的参数值,并且根据具体需求灵活选择字体、方向和大小,否则可能会导致文本输出不符合预期。
| 函数声明 | 函数功能 |
|---|---|
void settime(struct time *timep); |
设置当前系统时间 |
| 参数: |
1 |
|
在上述的程序中,
struct time 类型的变量 t,用于存储当前系统时间。然后使用 gettime() 函数获取当前时间,并将小时、分钟、秒和百分之一秒等信息存储到 t 变量的对应成员变量中。printf() 函数输出了当前的分钟数、小时数、百分之一秒数和秒数。这里使用了 %d 占位符来指定输出整数类型的值。注意 : 这个程序依赖于 DOS 系统提供的日期和时间相关函数,可能无法在其他操作系统或环境下运行。此外,直接修改系统时间可能会对计算机的正常运行产生影响,因此应该谨慎使用。
在现代的 Windows 操作系统中,DOS 环境已经被废弃,因此这个程序可能无法正常工作。如果要获取和修改当前系统时间,可以使用操作系统提供的相关 API 或系统调用接口实现。例如,在 Windows 平台上,可以使用 GetSystemTime() 和 SetSystemTime() 等函数来获取和设置系统时间。
| 函数声明 | 函数功能 |
|---|---|
void setusercharsize(int multx, int dirx, int multy, int diry); |
用于设置用户定义的字符大小 |
参数:
1 或 -1。当 dirx 的值为 1 时,字符不进行左右翻转;当 dirx 的值为 -1 时,字符进行左右翻转1 或 -1。当 diry 的值为 1 时,字符不进行上下翻转;当 diry 的值为 -1 时,字符进行上下翻转。1 |
|
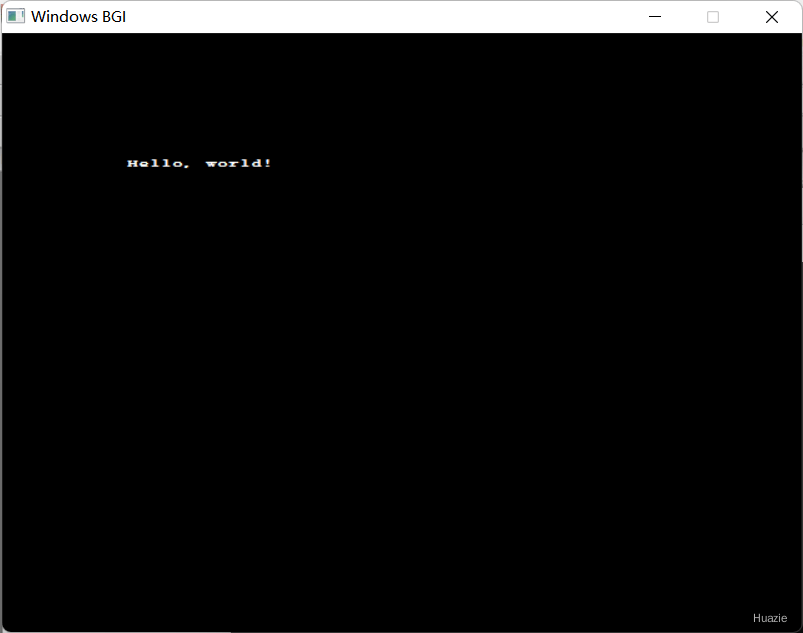
在上述这个示例程序中,我们使用 setusercharsize() 函数将当前字符的大小设置为水平方向放大 2 倍、垂直方向放大 3 倍,然后使用 outtextxy() 函数在窗口的指定位置输出一行文本。
注意: 在使用 setusercharsize() 函数设置字符大小时,必须指定正确的参数值,并且考虑到水平和垂直方向的缩放倍数,否则可能会导致字符输出不符合预期。
| 函数声明 | 函数功能 |
|---|---|
int setvbuf(FILE *stream, char *buf, int type, unsigned size); |
用于设置文件流的缓冲方式 |
参数:
stdin)、标准输出流(stdout)或标准错误流(stderr),也可以是通过 fopen() 函数打开的文件指针NULL。如果 buf 参数为 NULL,则 setvbuf() 函数将自动为文件流分配一块缓冲区_IONBF:不使用缓冲区,直接从或向设备读写数据_IOLBF:行缓冲,每行数据结束后刷新缓冲区_IOFBF:全缓冲,填满缓冲区后才进行读写操作buf 参数不为 NULL,则 size 参数指定了缓冲区大小;如果 buf 参数为 NULL,则 size 参数指定了系统为缓冲区分配的大小。size 参数只对全缓冲方式有效,行缓冲和无缓存方式忽略该参数1 |
|
在上述的示例程序中,
input 和 output,分别表示输入文件和输出文件。fopen() 函数打开输入文件和输出文件,并将返回的文件指针保存到对应的变量中。setvbuf() 函数分别为输入文件和输出文件设置缓冲方式。对于输入文件,使用 _IOFBF 缓冲类型和大小为 512 字节的缓冲区;对于输出文件,使用 _IOLBF 缓冲类型和大小为 132 字节的缓冲区(此处 bufr 缓冲区为空指针)。在设置完缓冲方式后,程序根据 setvbuf() 函数的返回值判断是否设置成功,如果返回值不为 0,则说明设置失败,否则说明设置成功,并输出相应的提示信息。fclose() 函数关闭输入文件和输出文件。注意: 在使用文件流进行读写操作时,必须在适当的时候进行缓冲区清理操作,以避免数据丢失或者读取到过期数据等问题。另外,需要根据具体需求选择合适的缓冲方式和缓冲区大小,以实现最优的性能和稳定性。
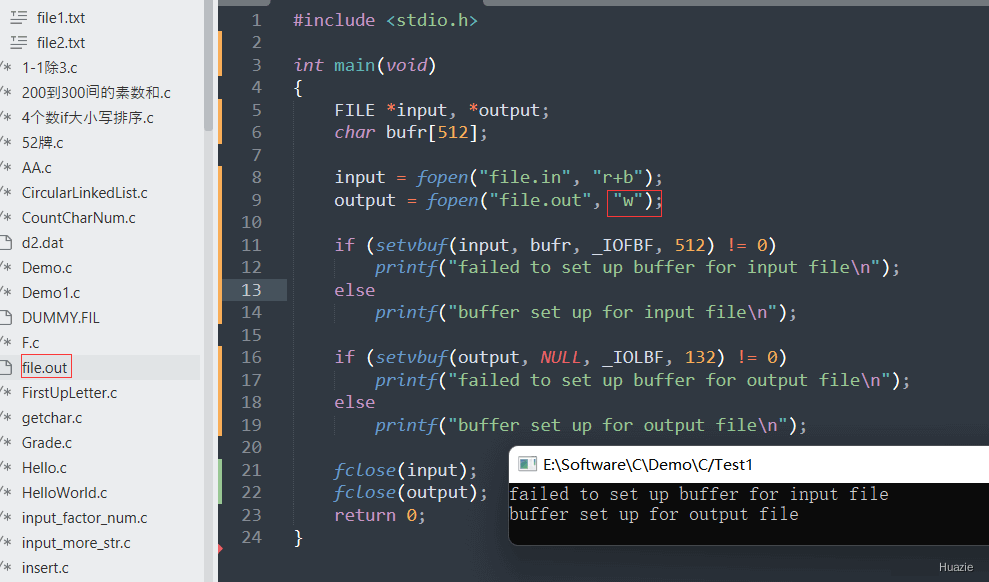
| 函数声明 | 函数功能 |
|---|---|
void setviewport(int left, int top, int right, int bottom, int clipflag); |
用于设置绘图窗口的视口范围 |
参数:
CLIP_ON:开启裁剪模式,只显示视口内的图形;CLIP_OFF:关闭裁剪模式,显示整个画面。1 |
|
在上面的示例程序中,
rectangle() 函数绘制了一个红色的矩形;setviewport() 函数将视口范围设置为矩形 (150, 150) - (250, 250);rectangle() 函数绘制了一个绿色的矩形,但这里只有在视口范围的矩形才显示出来。注意: 在使用 setviewport() 函数设置视口范围时,必须指定正确的参数值,并考虑到裁剪模式的影响,否则可能会导致图形显示不符合预期。
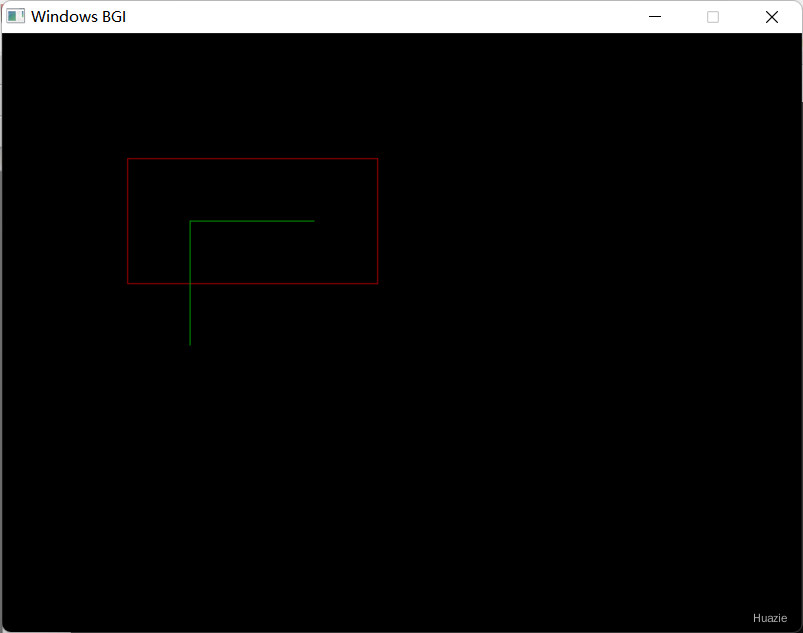
| 函数声明 | 函数功能 |
|---|---|
void setvisualpage(int pagenum); |
用于设置图形窗口中用户可见的页面 |
参数:
在双缓冲绘图中,我们通常会使用两个页面来绘制图像,一个是前台页面,另一个是后台页面。当我们绘制完一个完整的画面时,可以通过调用 setactivepage() 函数将后台页面切换到前台页面以显示出来。而 setvisualpage() 函数则用于设置用户当前看到的页面,它实际上是将指定的页面置于前台,从而更新屏幕上显示的内容。
1 |
|
上述示例将在屏幕上绘制两个页面,并允许用户通过按任意键查看第二个页面。
注意: setvisualpage() 函数只能用于已经创建的图形窗口,且参数 pagenum 必须在 0 到 getmaxpages() 函数返回值之间。

| 函数声明 | 函数功能 |
|---|---|
void setwritemode(int mode); |
用于设置绘画操作的写入模式 |
参数:
COPY_PUT:0,复制模式(默认),新绘制的图形将完全覆盖旧图形XOR_PUT:1,异或模式,新绘制的图形将与旧图形进行异或运算后显示。在这种模式下,如果一个像素既在新图形中出现过,也在旧图形中出现过,则它最终不会被显示出来;如果一个像素只在新图形中出现过,或者只在旧图形中出现过,则它将会被显示出来。OR_PUT:2,或模式,新绘制的图形将与旧图形进行或运算后显示。在这种模式下,如果一个像素既在新图形中出现过,也在旧图形中出现过,则它最终会被显示出来;如果一个像素只在新图形中出现过,或者只在旧图形中出现过,则它将会被显示出来。1 |
|
注意: setwritemode() 函数只对紧随其后的绘画操作生效,它不会影响之前已经绘制的图形。因此,在更改写入模式之前,必须先完成之前的绘画操作。
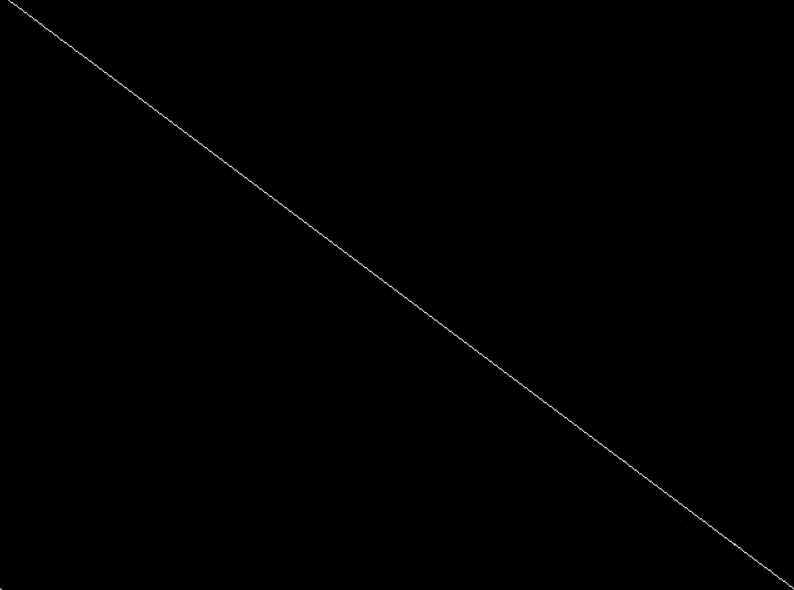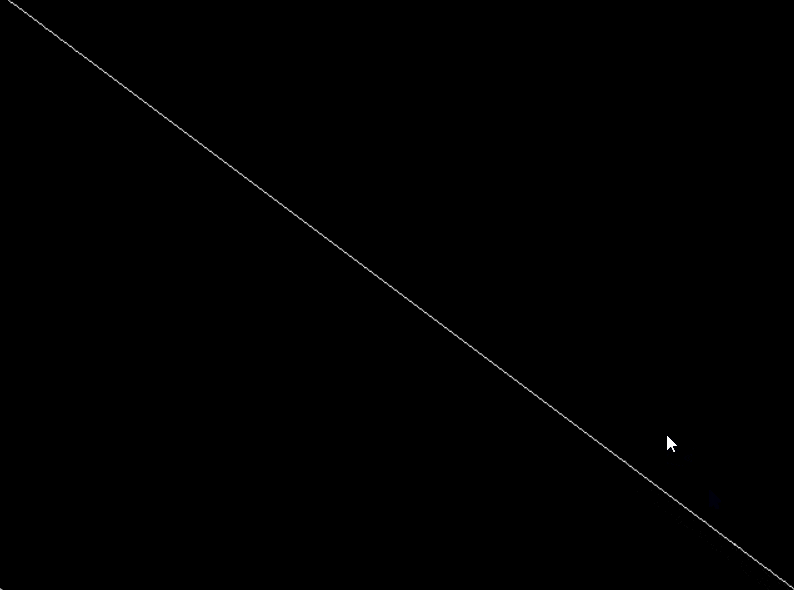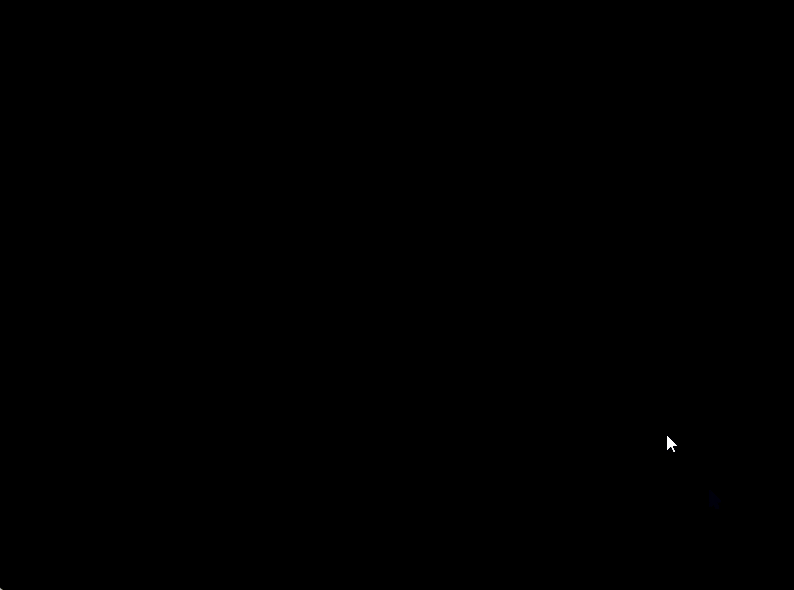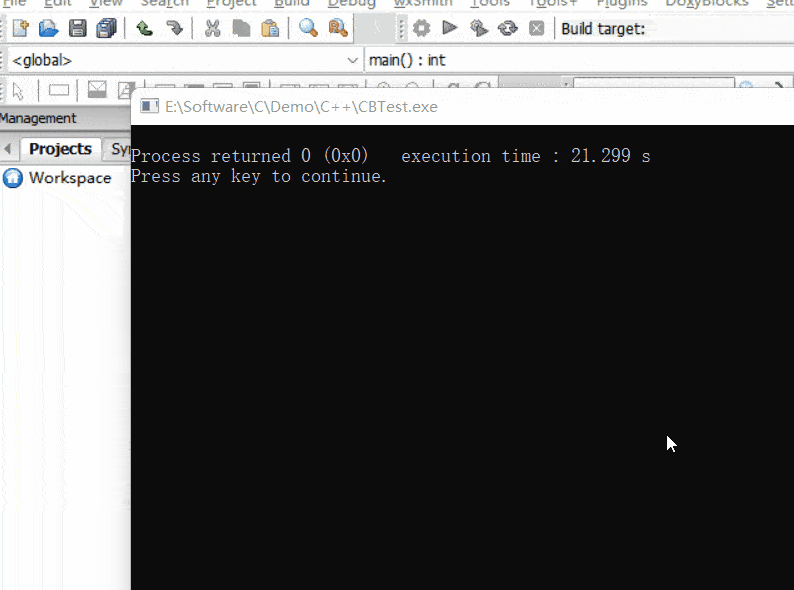
| 函数声明 | 函数功能 |
|---|---|
void (*signal(int signum, void (*handler)(int)))(int); |
用于设置指定信号的处理方式。当系统接收到某个信号时,会调用相应的信号处理函数来处理该信号。在调用 signal 函数时,需要指定要处理的信号以及相应的信号处理函数。 |
参数:
SIGINT(中断信号):通常由用户按下 “Ctrl + C“ 产生,用于中断正在运行的程序。SIGALRM(闹钟信号):用于在指定的时间后向进程发送信号,可以用于实现定时器等功能。SIGFPE(浮点异常信号):在发生浮点运算异常时发送该信号。SIGSEGV(段错误信号):在访问非法的内存地址时发送该信号。void handler(int)返回值:
SIG_DFL 或 SIG_IGN)。SIG_ERR。1 |
|
在上面的示例中,
signal() 函数设置了一个处理 SIGINT 信号的处理程序 sigint_handler()。
| 函数声明 | 函数功能 |
|---|---|
double significand(double x); |
用于分离浮点数 x 的尾数部分(double) |
float significandf(float x); |
用于分离浮点数 x 的尾数部分(float) |
参数:
1 |
|
注意: 在某些旧版本的编译器中,可能没有实现 significand 函数。这个时候可以考虑使用其他类似的函数来替代,如 frexp、modf 等。
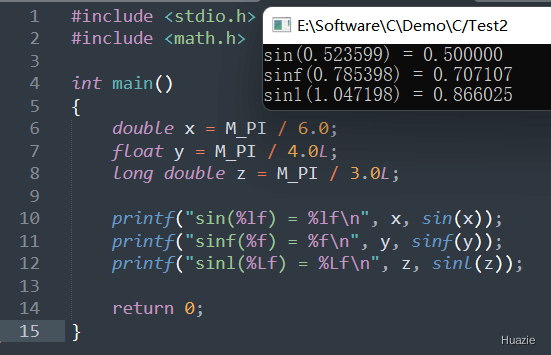
| 函数声明 | 函数功能 |
|---|---|
double sin(double x); |
用于计算一个角度(以弧度为单位)的正弦值(double) |
float sinf(float x); |
用于计算一个角度(以弧度为单位)的正弦值(float) |
long double sinl(long double x); |
用于计算一个角度(以弧度为单位)的正弦值(long double) |
参数:
1 |
|
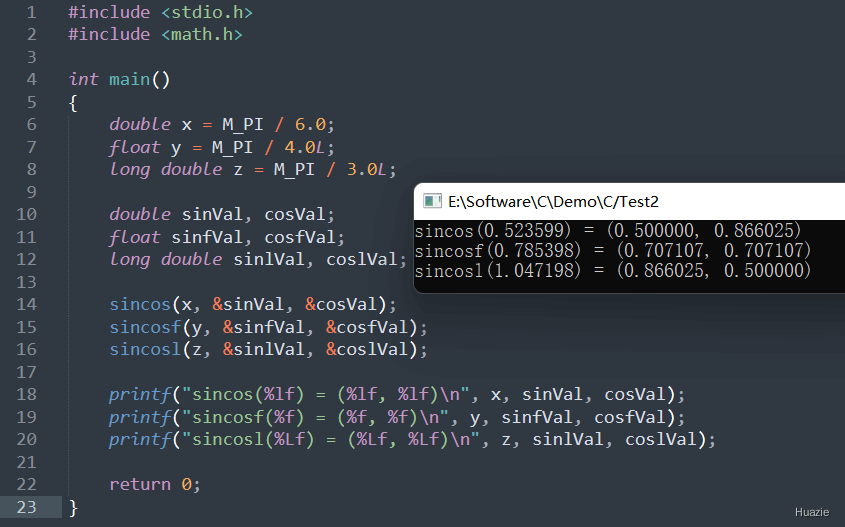
| 函数声明 | 函数功能 |
|---|---|
void sincos(double x, double* sinVal, double* cosVal); |
用于同时计算一个角度(以弧度为单位)的正弦值和余弦值 |
void sincosf(float x, float* sinVal, float* cosVal); |
用于同时计算一个角度(以弧度为单位)的正弦值和余弦值 |
void sincosl(long double x, long double* sinVal, long double* cosVal); |
用于同时计算一个角度(以弧度为单位)的正弦值和余弦值 |
参数:
1 |
|
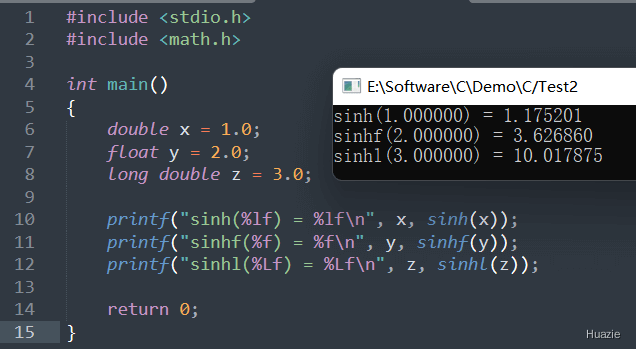
| 函数声明 | 函数功能 |
|---|---|
double sinh(double x); |
用于计算一个数的双曲正弦值 |
float sinhf(float x); |
用于计算一个数的双曲正弦值 |
long double sinhl(long double x); |
用于计算一个数的双曲正弦值 |
参数:
1 |
|